Chapter 3. File I/O¶
This chapter discusses unbuffered I/O, which are not part of ISO C but are part of POSIX.1 and the Single UNIX Specification.
File Descriptors¶
- All open files are referred to by file descriptors
- Non-negative integer
- Range from 0 to
OPEN_MAX - 1. With FreeBSD 8.0, Linux 3.2.0, Mac OS X 10.6.8, and Solaris 10, the limit is essentially infinite, bounded by the amount of memory on the system, the size of an integer, and any hard and soft limits configured by the system administrator.
open and openat Functions¶
#include <fcntl.h> int open(const char *path, int oflag, ... /* mode_t mode */ ); int openat(int fd, const char *path, int oflag, ... /* mode_t mode */ ); /* Both return: file descriptor if OK, −1 on error */
oflag argument is formed by ORing one or more of the following constants from <fcntl.h> [p62]:
Required:
O_RDONLYO_WRONLYO_RDWRO_EXECO_SEARCH: Open for search only (applies to directories).
Optional:
O_APPENDO_CLOEXEC: Set theFD_CLOEXECfile descriptor flagO_CREAT: Create the file if it doesn’t existO_DIRECTORY: Generate an error ifO_CREATis also specified and the file already exists. This test for whether the file already exists and the creation of the file if it doesn’t exist is an atomic operationO_EXCLO_NOCTTYO_NOFOLLOWO_NONBLOCKO_SYNC: Have eachwritewait for physical I/O to completeO_TRUNCO_TTY_INITO_DSYNCO_RSYNC
TOCTTOU¶
openat, for example, provides a way to avoid time-of-check-to-time-of-use (TOCTTOU) errors. A program is vulnerable if it makes two file-based function calls where the second call depends on the results of the first call (two calls are not atomic).
Filename and Pathname Truncation¶
Most modern file systems support a maximum of 255 characters for filenames.
creat Function¶
#include <fcntl.h> int creat(const char *path, mode_t mode); /* Returns: file descriptor opened for write-only if OK, −1 on error */
This function is equivalent to:
open(path, O_WRONLY | O_CREAT | O_TRUNC, mode);
With creat, the file is opened only for writing. To read and write a file, use [p66]:
open(path, O_RDWR | O_CREAT | O_TRUNC, mode);
close Function¶
#include <unistd.h> int close(int fd); /* Returns: 0 if OK, −1 on error */
When a process terminates, all of its open files are closed automatically by the kernel. Many programs take advantage of this fact and don’t explicitly close open files.
lseek Function¶
Every open file has a "current file offset", normally a non-negative integer that measures the number of bytes from the beginning of the file.
#include <unistd.h> off_t lseek(int fd, off_t offset, int whence); /* Returns: new file offset if OK, −1 on error */
The whence argument can be:
SEEK_SET: the file’s offset is set to offset bytes from the beginning of the fileSEEK_CUR: the file’s offset is set to its current value plus the offset. The offset can be positive or negative.SEEK_END: the file’s offset is set to the size of the file plus the offset. The offset can be positive or negative.
To determine the current offset, seek zero bytes from the current position:
off_t currpos; currpos = lseek(fd, 0, SEEK_CUR);
This technique (above code) can also be used to determine if a file is capable of seeking. If the file descriptor refers to a pipe, FIFO, or socket, lseek sets errno to ESPIPE and returns −1.
- Negative offsets are possible for certain devices, but for regular files, the offset must be non-negative.
lseekonly records the current file offset within the kernel and does not cause any I/O to take place. This offset is then used by the next read or write operation.- Hole in a file: file’s offset can be greater than the file’s current size, in which case the next
writeto the file will extend the file. This creates a hole in the file.- Bytes in the hole (bytes that have not been writen) are read back as 0.
- A hole in a file isn’t required to have storage backing it on disk.
read Function¶
#include <unistd.h> ssize_t read(int fd, void *buf, size_t nbytes); /* Returns: number of bytes read, 0 if end of file, −1 on error */
- buf: type
void *is used for generic pointers. - Return value is required to be a signed integer (
ssize_t) to return a positive byte count, 0 (for end of file), or −1 (for an error).
Several cases in which the number of bytes actually read is less than the amount requested:
- Regular file: if the end of file is reached before the requested number of bytes has been read.
- Terminal device: up to one line is read at a time
- Network: buffering within the network may cause less than the requested amount to be returned
- Pipe or FIFO: if the pipe contains fewer bytes than requested,
readwill return only what is available - Record-oriented device
- Interrupted by a signal and a partial amount of data has already been read
write Function¶
#include <unistd.h> ssize_t write(int fd, const void *buf, size_t nbytes); /* Returns: number of bytes written if OK, −1 on error */
The return value is usually equal to the nbytes argument; otherwise, an error has occurred.
Common causes for a write error:
- Filling up a disk
- Exceeding the file size limit for a given process
For a regular file, the write operation starts at the file’s current offset. If the O_APPEND option was specified when the file was opened, the file’s offset is set to the current end of file before each write operation. After a successful write, the file’s offset is incremented by the number of bytes actually written.
I/O Efficiency¶
#include "apue.h" #define BUFFSIZE 4096 int main(void) { int n; char buf[BUFFSIZE]; while ((n = read(STDIN_FILENO, buf, BUFFSIZE)) > 0) if (write(STDOUT_FILENO, buf, n) != n) err_sys("write error"); if (n < 0) err_sys("read error"); exit(0); }
Caveats of the above program:
- It reads from standard input and writes to standard output, assuming that these have been set up by the shell before this program is executed.
- It doesn’t close the input file or output file. Instead, the program uses the feature of the UNIX kernel that closes all open file descriptors in a process when that process terminates.
- This example works for both text files and binary files, since there is no difference between the two to the UNIX kernel.
Timing results for reading with different buffer sizes (BUFFSIZE) on Linux:
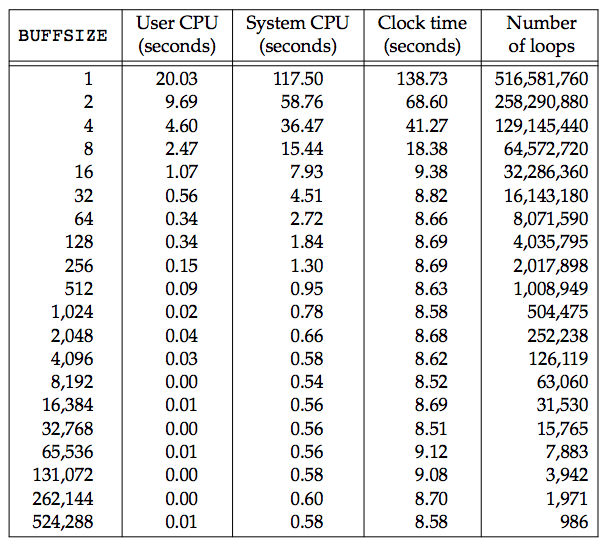
The file was read using the program shown above, with standard output redirected to /dev/null. The file system used for this test was the Linux ext4 file system with 4,096-byte blocks (the st_blksize value is 4,096). This accounts for the minimum in the system time occurring at the few timing measurements starting around a BUFFSIZE of 4,096. Increasing the buffer size beyond this limit has little positive effect.
Most file systems support some kind of read-ahead to improve performance. When sequential reads are detected, the system tries to read in more data than an application requests, assuming that the application will read it shortly. The effect of read-ahead can be seen in Figure 3.6, where the elapsed time for buffer sizes as small as 32 bytes is as good as the elapsed time for larger buffer sizes. [p73]
File Sharing¶
The UNIX System supports the sharing of open files among different processes.
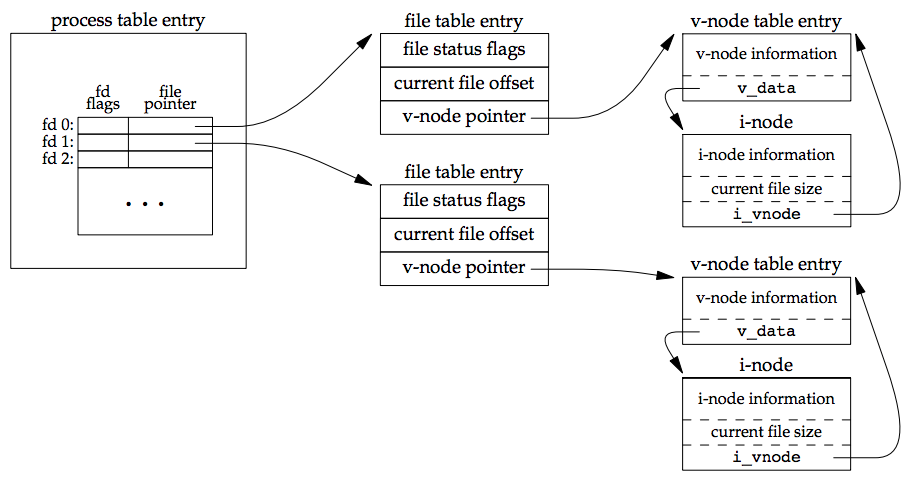
The kernel uses three data structures to represent an open file, and the relationships among them determine the effect one process has on another with regard to file sharing.
- Process table entry: every process has an entry in the process table. Each process table entry has a table of open file descriptors. Associated with each file descriptor are:
- File descriptor flags (close-on-exec)
- Pointer to a file table entry:
- File table entry: the kernel maintains a file table for all open files. Each file table entry contains:
- File status flags
- Current file offset
- Pointer to the v-node table entry for the file
- v-node structure: contains information about the type of file and pointers to functions that operate on the file
- This information is read from disk when the file is opened, so that all the pertinent information about the file is readily available
- v-node also contains the i-node for the file
- Linux has no v-node. Instead, a generic i-node structure is used. [p75] Instead of splitting the data structures into a v-node and an i-node, Linux uses a file system–independent i-node and a file system–dependent i-node. [p76]
Figure 3.7 shows a pictorial arrangement of these three tables for a single process that has two different files open: one file is open on standard input (file descriptor 0), and the other is open on standard output (file descriptor 1).
If two independent processes have the same file open, we could have the arrangement shown in Figure 3.8 (below).
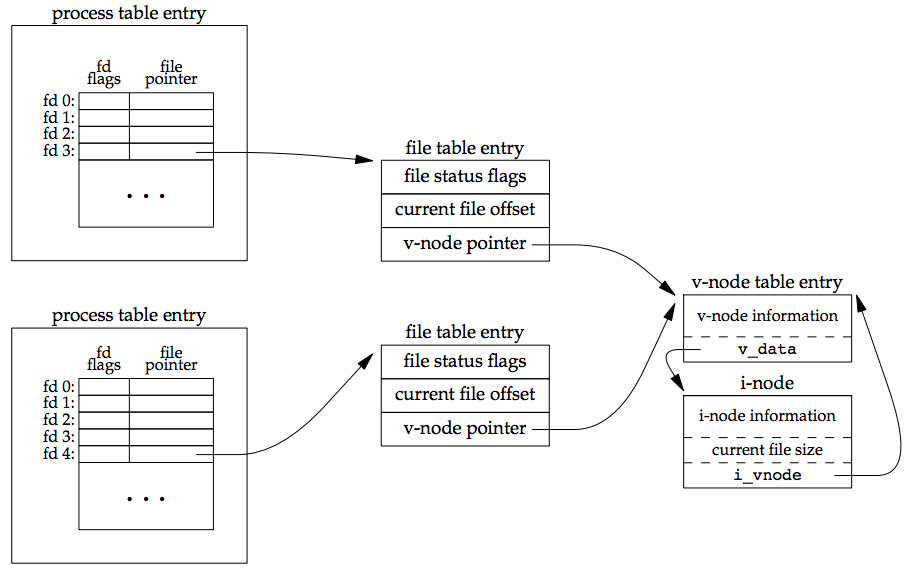
Each process that opens the file gets its own file table entry, but only a single v-node table entry is required for a given file. One reason each process gets its own file table entry is so that each process has its own current offset for the file.
Specific operations¶
- File offset: After each
writeis complete, the current file offset in the file table entry is incremented by the number of bytes written. If this causes the current file offset to exceed the current file size, the current file size in the i-node table entry is set to the current file offset (the file is extended). O_APPEND: If a file is opened with theO_APPENDflag, a corresponding flag is set in the file status flags of the file table entry. Each time awriteis performed for a file with this append flag set, the current file offset in the file table entry is first set to the current file size from the i-node table entry. Th is forces everywriteto be appended to the current end of file.lseek- If a file is positioned to its current end of file using
lseek, all that happens is the current file offset in the file table entry is set to the current file size from the i-node table entry. This is not the same as if the file was opened with theO_APPENDflag. - The
lseekfunction modifies only the current file offset in the file table entry. No I/O takes place.
- If a file is positioned to its current end of file using
It is possible for more than one file descriptor entry to point to the same file table entry:
dupfork: the parent and the child share the same file table entry for each open descriptor
File descriptor flags vs. the file status flags¶
- File descriptor flags: apply only to a single descriptor in a single process
- File status flags: apply to all descriptors in any process that point to the given file table entry
fcntlis used to fetch and modify both of them
Atomic Operations¶
Older versions of the UNIX System didn’t support the O_APPEND option if a single process wants to append to the end of a file. The program would be:
if (lseek(fd, 0L, 2) < 0) /* position to EOF, 2 means SEEK_END */ err_sys("lseek error"); if (write(fd, buf, 100) != 100) /* and write */ err_sys("write error");
This works fine for a single process, but problems arise if multiple processes (or multiple instances of the same program) use this technique to append to the same file. The problem here is that our logical operation of "position to the end of file and write" requires two separate function calls. The solution is to have the positioning to the current end of file and the write be an atomic operation with regard to other processes. Any operation that requires more than one function call cannot be atomic, as there is always the possibility that the kernel might temporarily suspend the process between the two function calls. The UNIX System provides an atomic way to do this operation if we set the O_APPEND flag when a file is opened. This causes the kernel to position the file to its current end of file before each write. We no longer have to call lseek before each write.
pread and pwrite Functions¶
The Single UNIX Specification includes two functions that allow applications to seek and perform I/O atomically:
#include <unistd.h> ssize_t pread(int fd, void *buf, size_t nbytes, off_t offset); /* Returns: number of bytes read, 0 if end of file, −1 on error */ ssize_t pwrite(int fd, const void *buf, size_t nbytes, off_t offset); /* Returns: number of bytes written if OK, −1 on error */
pread: equivalent to callinglseekfollowed by a call toread, with the following exceptions:- There is no way to interrupt the two operations that occur calling
pread. - The current file offset is not updated.
- There is no way to interrupt the two operations that occur calling
pwrite: equivalent to calling lseek followed by a call to write, with similar exceptions topread.
Creating a File¶
Atomic operation¶
When both of O_CREAT and O_EXCL options are specified, the open will fail if the file already exists. The check for the existence of the file and the creation of the file was performed as an atomic operation.
Non-atomic operation¶
If we didn’t have this atomic operation, we might try:
if ((fd = open(path, O_WRONLY)) < 0) { if (errno == ENOENT) { if ((fd = creat(path, mode)) < 0) err_sys("creat error"); } else { err_sys("open error"); } }
The problem occurs if the file is created by another process between the open and the creat. If the file is created by another process between these two function calls, and if that other process writes something to the file, that data is erased when this creat is executed. Combining the test for existence and the creation into a single atomic operation avoids this problem.
Atomic operation refers to an operation that might be composed of multiple steps. If the operation is performed atomically, either all the steps are performed (on success) or none are performed (on failure). It must not be possible for only a subset of the steps to be performed.
dup and dup2 Functions¶
An existing file descriptor is duplicated by either of the following functions:
#include <unistd.h> int dup(int fd); int dup2(int fd, int fd2); /* Both return: new file descriptor if OK, −1 on error */
dup: return the new file descriptor, which is guaranteed to be the lowest-numbered available file descriptordup2: fd2 argument is the new file descriptor we specifiy.- If fd2 is already open, it is first closed
- If fd equals fd2, then
dup2returns fd2 without closing it. Otherwise, theFD_CLOEXECfile descriptor flag is cleared for fd2, so that fd2 is left open if the process callsexec.
Kernel data structures after dup(1):

In the above figure, we assume the process executes:
newfd = dup(1);
- Because both descriptors point to the same file table entry, they share the same file status flags (e.g. read, write, append) and the same current file offset.
- Each descriptor has its own set of file descriptor flags
Another way to duplicate a descriptor is with the fcntl function:
dup(fd);
is equivalent to
fcntl(fd, F_DUPFD, 0);
Similarly, the call
dup2(fd, fd2);
is equivalent to
close(fd2); fcntl(fd, F_DUPFD, fd2);
In this last case (above), the dup2 is not exactly the same as a close followed by an fcntl:
dup2is an atomic operation, whereas the alternate form involves two function calls. It is possible in the latter case to have a signal catcher called between thecloseand thefcntlthat could modify the file descriptors. The same problem could occur if a different thread changes the file descriptors.- There are some
errnodifferences betweendup2andfcntl.
sync, fsync, and fdatasync Functions¶
Traditional implementations of the UNIX System have a buffer cache or page cache in the kernel through which most disk I/O passes.
- Delayed write: when we write data to a file, the data is normally copied by the kernel into one of its buffers and queued for writing to disk at some later time
The kernel eventually writes all the delayed-write blocks to disk, normally when it needs to reuse the buffer for some other disk block. To ensure consistency of the file system on disk with the contents of the buffer cache, the sync, fsync, and fdatasync functions are provided.
#include <unistd.h> int fsync(int fd); int fdatasync(int fd); /* Returns: 0 if OK, −1 on error */ void sync(void);
sync: queues all the modified block buffers for writing and returns. It does not wait for the disk writes to take placesyncis normally called periodically (usually every 30 seconds) from a system daemon, often calledupdate, which guarantees regular flushing of the kernel’s block buffers. The commandsync(1)also calls thesyncfunction.
fsync: applies to a single file specified by the file descriptor fd, and waits for the disk writes to complete before returning.fsyncalso updates the file's attributes synchronously
fdatasync: similar tofsync, but it affects only the data portions of a file.
fcntl Function¶
The fcntl function can change the properties of a file that is already open.
#include <fcntl.h> int fcntl(int fd, int cmd, ... /* int arg */ ); /* Returns: depends on cmd if OK (see following), −1 on error */
In this section, the third argument of fcntl is always an integer, corresponding to the comment in the function prototype just shown.
The fcntl function is used for five different purposes:
- Duplicate an existing descriptor (cmd =
F_DUPFDorF_DUPFD_CLOEXEC) - Get/set file descriptor flags (cmd =
F_GETFDorF_SETFD) - Get/set file status flags (cmd =
F_GETFLorF_SETFL) - Get/set asynchronous I/O ownership (cmd =
F_GETOWNorF_SETOWN) - Get/set record locks (cmd =
F_GETLK,F_SETLK, orF_SETLKW)
The following text discusses both the file descriptor flags associated with each file descriptor in the process table entry and the file status flags associated with each file table entry.
F_DUPFD: Duplicate the file descriptor fd. The new file descriptor, which is the lowest-numbered descriptor that is not already open and is greater than or equal to the third argument (integer), is returned as the value of the function. The new descriptor has its own set of file descriptor flags withFD_CLOEXECcleared. cleared.F_DUPFD_CLOEXEC: Duplicate the file descriptor and set theFD_CLOEXECfile descriptor flag associated with the new descriptor.F_GETFD: Return the file descriptor flags for fd. Currently, only one file descriptor flag (FD_CLOEXEC) is defined.F_SETFD: Set the file descriptor flags for fd. The new flag value is set from the third argument.- Some existing programs don’t use constant
FD_CLOEXEC. Instead, these programs set the flag to either 0 (don’t close-on-exec, the default) or 1 (do close-on-exec).
- Some existing programs don’t use constant
-
F_GETFL: Return the file status flags for fd. The file status flags were described with theopenfunction.- The five access-mode flags (
O_RDONLY,O_WRONLY,O_RDWR,O_EXEC, andO_SEARCH) are not separate bits that can be tested. O_RDONLY,O_WRONLY,O_RDWRoften have the values 0, 1, and 2, respectively- The five access-mode flags are mutually exclusive: this means a file can have only one of them enabled.
- We must first use the
O_ACCMODEmask to obtain the access-mode bits and then compare the result against any of the five values.
File status flag Description O_RDONLYopen for reading only O_WRONLYopen for writing only O_RDWRopen for reading and writing O_EXECopen for execute only O_SEARCHopen directory for searching only O_APPENDappend on each write O_NONBLOCKnonblocking mode O_SYNCwait for writes to complete (data and attributes) O_DSYNCwait for writes to complete (data only) O_RSYNCsynchronize reads and writes O_FSYNCwait for writes to complete (FreeBSD and Mac OS X only) O_ASYNCasynchronous I/O (FreeBSD and Mac OS X only) - The five access-mode flags (
-
F_SETFL: Set the file status flags to the value of the third argument (integer). The only flags that can be changed are:O_APPENDO_NONBLOCKO_SYNCO_DSYNCO_RSYNCO_FSYNCO_ASYNC
F_GETOWN: Get the process ID or process group ID currently receiving theSIGIOandSIGURGsignals.F_SETOWN: Set the process ID or process group ID to receive theSIGIOandSIGURGsignals.
The return value from fcntl depends on the command. All commands return −1 on an error or some other value if OK. The following four commands have special return values:
F_DUPFD: returns the new file descriptorF_GETFD: returns the file descriptor flagsF_GETFL: returns the file status flagsF_GETOWN: returns a positive process ID or a negative process group ID
Getting file flags¶
Example:
#include "apue.h" #include <fcntl.h> int main(int argc, char *argv[]) { int val; if (argc != 2) err_quit("usage: a.out <descriptor#>"); if ((val = fcntl(atoi(argv[1]), F_GETFL, 0)) < 0) err_sys("fcntl error for fd %d", atoi(argv[1])); switch (val & O_ACCMODE) { case O_RDONLY: printf("read only"); break; case O_WRONLY: printf("write only"); break; case O_RDWR: printf("read write"); break; default: err_dump("unknown access mode"); } if (val & O_APPEND) printf(", append"); if (val & O_NONBLOCK) printf(", nonblocking"); if (val & O_SYNC) printf(", synchronous writes"); #if !defined(_POSIX_C_SOURCE) && defined(O_FSYNC) && (O_FSYNC != O_SYNC) if (val & O_FSYNC) printf(", synchronous writes"); #endif putchar('\n'); exit(0); }
Results:
$ ./a.out 0 < /dev/tty read only $ ./a.out 1 > temp.foo $ cat temp.foo write only $ ./a.out 2 2>>temp.foo write only, append $ ./a.out 5 5<>temp.foo read write
Modifying file flags¶
To modify either the file descriptor flags or the file status flags, we must be careful to fetch the existing flag value, modify it as desired, and then set the new flag value. We can’t simply issue an F_SETFD or an F_SETFL command, as this could turn off flag bits that were previously set.
Example:
#include "apue.h" #include <fcntl.h> void set_fl(int fd, int flags) /* flags are file status flags to turn on */ { int val; if ((val = fcntl(fd, F_GETFL, 0)) < 0) err_sys("fcntl F_GETFL error"); val |= flags; /* turn on flags */ if (fcntl(fd, F_SETFL, val) < 0) err_sys("fcntl F_SETFL error"); }
If we change the middle statement to
val &= ~flags; /* turn flags off */
we have a function named clr_fl, logically ANDs the one’s complement of flags with the current val.
Synchronous-write flag¶
If we add the line
set_fl(STDOUT_FILENO, O_SYNC);
to the beginning of the program shown in I/O Efficiency section, we’ll turn on the synchronous-write flag. This causes each write to wait for the data to be written to disk before returning. Normally in the UNIX System, a write only queues the data for writing; the actual disk write operation can take place sometime later. A database system is a likely candidate for using O_SYNC, so that it knows on return from a write that the data is actually on the disk, in case of an abnormal system failure.
Linux ext4 timing results using various synchronization mechanisms [p86]
Mac OS X HFS timing results using various synchronization mechanisms [p87]
The above program operates on a descriptor (standard output), never knowing the name of the file that was opened on that descriptor. We can’t set the O_SYNC flag when the file is opened, since the shell opened the file. With fcntl, we can modify the properties of a descriptor, knowing only the descriptor for the open file.
ioctl Function¶
#include <unistd.h> /* System V */ #include <sys/ioctl.h> /* BSD and Linux */ int ioctl(int fd, int request, ...); /* Returns: −1 on error, something else if OK */
The ioctl function has always been the catchall for I/O operations. Anything that couldn’t be expressed using one of the other functions in this chapter usually ended up being specified with an ioctl. Terminal I/O was the biggest user of this function.
For the ISO C prototype, an ellipsis is used for the remaining arguments. Normally, however, there is only one more argument, and it’s usually a pointer to a variable or a structure.
Each device driver can define its own set of ioctl commands. The system, however, provides generic ioctl commands for different classes of devices.
We use the ioctl function in Section 18.12 to fetch and set the size of a terminal’s window, and in Section 19.7 when we access the advanced features of pseudo terminals.
/dev/fd¶
Newer systems provide a directory named /dev/fd whose entries are files named 0, 1, 2, and so on. Opening the file /dev/fd/n is equivalent to duplicating descriptor n, assuming that descriptor n is open. /dev/fd is not part of POSIX.1.
The following are equivalent:
fd = open("/dev/fd/0", mode); fd = dup(0);
Most systems ignore the specified mode, whereas others require that it be a subset of the mode used when the referenced file (standard input, in this case) was originally opened. The descriptors 0 and fd share the same file table entry.
The Linux implementation of /dev/fd is an exception. It maps file descriptors into symbolic links pointing to the underlying physical files. When you open /dev/fd/0, for example, you are really opening the file associated with your standard input. Thus the mode of the new file descriptor returned is unrelated to the mode of the /dev/fd file descriptor.
We can also call creat with a /dev/fd pathname argument as well as specify O_CREAT in a call to open. This allows a program that calls creat to still work if the pathname argument is /dev/fd/1, for example.
Some systems provide the pathnames /dev/stdin, /dev/stdout, and /dev/stderr. These pathnames are equivalent to /dev/fd/0, /dev/fd/1, and /dev/fd/2, respectively.
The main use of the /dev/fd files is from the shell. It allows programs that use pathname arguments to handle standard input and standard output in the same manner as other pathnames.
The following are equivalent:
filter file2 | cat file1 - file3 | lpr filter file2 | cat file1 /dev/fd/0 file3 | lpr