Chapter 3. Basic Data Types¶
Computers operate fundamentally on fixed-size numbers called words, which are interpreted as integers, floating-point numbers, bit sets, or memory addresses, then combined into larger aggregates.
Go’s types fall into four categories:
- Basic types: numbers, strings, and booleans.
- Aggregate types: arrays and structs.
- Reference types: pointers, slices, maps, functions, and channels .
- Interface types
Basic types (discussed in this chapter) include numbers, strings, and booleans.
Integers¶
Go provides both signed and unsigned integer arithmetic. There are four distinct sizes of signed integers: 8, 16, 32, and 64 bits. They represented by:
- Signed:
int8,int16,int32, andint64; - Unsigned:
uint8,uint16,uint32, anduint64.
There are also two types int and uint that are the natural or most efficient size for signed and unsigned integers on a particular platform: int is by far the most widely used numeric type. Both these types have the same size, either 32 or 64 bits, but one must not make assumptions about which; different compilers may make different choices even on identical hardware.
- The type
runeis an synonym forint32and conventionally indicates that a value is a Unicode code point. The two names may be used interchangeably. - The type
byteis an synonym foruint8, and emphasizes that the value is a piece of raw data rather than a small numeric quantity. uintptris an unsigned integer type, whose width is not specified but is sufficient to hold all the bits of a pointer value. Theuintptrtype is used only for low-level programming, such as at the boundary of a Go program with a C library or an operating system (discussed with theunsafepackage in Chapter 13).
Regardless of their size, int, uint, and uintptr are different types from their explicitly sized siblings. Thus int is not the same type as int32, even if the natural size of integers is 32 bits, and an explicit conversion is required to use an int value where an int32 is needed, and vice versa.
Signedness *¶
Signed numbers are represented in 2’s-complement form, in which the high-order bit is reserved for the sign of the number and the range of values of an n-bit number is from −2n−1 to 2n−1−1. Unsigned integers use the full range of bits for non-negative values and thus have the range 0 to 2n−1. For instance, the range of int8 is −128 to 127, whereas the range of uint8 is 0 to 255.
Binary operators *¶
Go’s binary operators for arithmetic, logic, and comparison are listed here in order of decreasing precedence:
* / % << >> & &^ + - | ^ == != < <= > >= && ||
There are only five levels of precedence for binary operators. Operators at the same level associate to the left; parentheses may be required for clarity, or to make the operators evaluate in the intended order in an expression like mask & (1 << 28).
Each operator in the first two lines of the table above, has a corresponding assignment operator. For instance, + has += that may be used to abbreviate an assignment statement.
Arithmetic operators *¶
The integer arithmetic operators +, -, *, and / may be applied to integer, floating-point, and complex numbers, but the remainder operator % applies only to integers.
- The behavior of
%for negative numbers varies across programming languages. In Go, the sign of the remainder is always the same as the sign of the dividend, so-5%3and-5%-3are both-2. - The behavior of
/depends on whether its operands are integers, so5.0/4.0is1.25, but5/4is1because integer division truncates the result toward zero.
Integer overflow *¶
If the result of an arithmetic operation, whether signed or unsigned, has more bits than can be represented in the result type, it is said to overflow. The high-order bits that do not fit are silently discarded. If the original number is a signed type, the result could be negative if the leftmost bit is a 1, as in the int8 example here:
var u uint8 = 255 fmt.Println(u, u+1, u*u) // "255 0 1" var i int8 = 127 fmt.Println(i, i+1, i*i) // "127 -128 1"
Comparison and comparability *¶
Binary comparison operators are:
==: equal to!=: not equal to<: less than<=: less than or equal to>: greater than>=: greater than or equal to
The type of a comparison expression is a boolean.
- All values of basic type (booleans, numbers, and strings) are comparable. This means two values of the same type may be compared using the
==and!=operators. - Integers, floating-point numbers, and strings are ordered by the comparison operators.
- The values of many other types are not comparable, and no other types are ordered.
Unary operators *¶
There are also unary addition and subtraction operators:
+: unary positive (no effect)-: unary negation
For integers, +x is a shorthand for 0+x and -x is a shorthand for 0-x; for floating-point and complex numbers, +x is just x and -x is the negation of x.
Bitwise binary operators *¶
The following are bitwise binary operators. The first four of them treat their operands as bit patterns with no concept of arithmetic carry or sign:
&: bitwise AND|: bitwise OR^: bitwise XOR&^: bit clear (AND NOT)<<: left shift>>: right shift
The operator ^ has two usages:
- When used as a binary operator, it is bitwise exclusive OR (XOR)
- When used as a unary prefix operator, it is bitwise negation or complement, which means it returns a value with each bit in its operand inverted.
The &^ operator is bit clear (AND NOT): in the expression z = x &^ y, each bit of z is 0 if the corresponding bit of y is 1; otherwise it equals the corresponding bit of x.
Bitwise operation examples *¶
The code below shows how bitwise operations can be used to interpret a uint8 value as a compact and efficient set of 8 independent bits. It uses Printf's %b verb to print a number’s binary digits; 08 modifies %b to pad the result with zeros to exactly 8 digits.
var x uint8 = 1<<1 | 1<<5 var y uint8 = 1<<1 | 1<<2 fmt.Printf("%08b\n", x) // "00100010", the set {1, 5} fmt.Printf("%08b\n", y) // "00000110", the set {1, 2} fmt.Printf("%08b\n", x&y) // "00000010", the intersection {1} fmt.Printf("%08b\n", x|y) // "00100110", the union {1, 2, 5} fmt.Printf("%08b\n", x^y) // "00100100", the symmetric difference {2, 5} fmt.Printf("%08b\n", x&^y) // "00100000", the difference {5} for i := uint(0); i < 8; i++ { if x&(1<<i) != 0 { // membership test fmt.Println(i) // "1", "5" } } fmt.Printf("%08b\n", x<<1) // "01000100", the set {2, 6} fmt.Printf("%08b\n", x>>1) // "00010001", the set {0, 4}
Section 6.5 shows an implementation of integer sets that can be much bigger than a byte.
In the shift operations x<<n and x>>n:
- The
noperand determines the number of bit positions to shift and must be unsigned. - The
xoperand may be unsigned or signed.
Arithmetically:
- A left shift
x<<nis equivalent to multiplication by 2n. - A right shift
x>>nis equivalent to the floor of division by 2n.
For unsigned numbers, both left and right shifts fill the vacated bits with zeros. However, right shifts of signed numbers fill the vacated bits with copies of the sign bit. For this reason, it is important to use unsigned arithmetic when you’re treating an integer as a bit pattern.
Usages of unsigned numbers¶
Although Go provides unsigned numbers and arithmetic, we tend to use the signed int form even for quantities that can’t be negative, such as the length of an array (though uint might seem a more obvious choice). The built-in len function returns a signed int. Consider the following example:
medals := []string{"gold", "silver", "bronze"} for i := len(medals) - 1; i >= 0; i-- { fmt.Println(medals[i]) // "bronze", "silver", "gold" }
If len returned an unsigned number, then i would be a uint, and the condition i >= 0 would always be true by definition. After the third iteration, in which i == 0, the i-- statement would cause i to become not −1, but the maximum uint value (for example, 264−1), and the evaluation of medals[i] would fail at run time, or panic (Section 5.9), by attempting to access an element outside the bounds of the slice.
For this reason, unsigned numbers tend to be used only when their bitwise operators or peculiar arithmetic operators are required, such as
- Implementing bit sets
- Parsing binary file formats
- For hashing and cryptography.
They are typically not used for merely non-negative quantities.
Binary operators for arithmetic and logic (except shifts) must have operands of the same type. In cases where operands have different types, an explicit conversion is required. This eliminates a whole class of problems and makes programs easier to understand.
Consider this sequence:
var apples int32 = 1 var oranges int16 = 2 var compote int = apples + oranges // compile error
Attempting to compile these three declarations produces an error message:
invalid operation: apples + oranges (mismatched types int32 and int16)
This type mismatch can be fixed in several ways, most directly by converting everything to a common type:
var compote = int(apples) + int(oranges)
As described in Section 2.5, for every type T, the conversion operation T(x) converts the value x to type T if the conversion is allowed. Many integer-to-integer conversions do not entail any change in value, but only tell the compiler how to interpret a value. However, some conversions may change the value or lose precision:
- A conversion that narrows a big integer into a smaller one.
- A conversion from integer to floating-point or vice versa.
f := 3.141 // a float64 i := int(f) fmt.Println(f, i) // "3.141 3" f = 1.99 fmt.Println(int(f)) // "1"
Float to integer conversion discards any fractional part, truncating toward zero. You should avoid conversions in which the operand is out of range for the target type, because the behavior depends on the implementation:
f := 1e100 // a float64 i := int(f) // result is implementation-dependent
Integer literals of any size and type can be written as one of the following:
- Ordinary decimal numbers,
- Octal numbers, if they begin with 0, e.g. 0666
- Hexadecimal, if they begin with 0x or 0X, e.g. 0xdeadbeef. Hex digits may be upper or lower case.
Nowadays octal numbers seem to be used for exactly one purpose: file permissions on POSIX systems. Hexadecimal numbers are widely used to emphasize the bit pattern of a number over its numeric value. When printing numbers using the fmt package, we can control the radix and format with the %d, %o, and %x verbs, as shown in this example:
o := 0666 fmt.Printf("%d %[1]o %#[1]o\n", o) // "438 666 0666" x := int64(0xdeadbeef) fmt.Printf("%d %[1]x %#[1]x %#[1]X\n", x) // Output: // 3735928559 deadbeef 0xdeadbeef 0XDEADBEEF
The above example describes two fmt tricks.
- Usually a
Printfformat string containing multiple%verbs would require the same number of extra operands, but the[1]"adverbs" after%tellPrintfto use the first operand. - The
#adverb for%oor%xor%XtellsPrintfto emit a0or0xor0Xprefix respectively.
Rune literals are written as a character within single quotes. The simplest example is an ASCII character like 'a', but it’s possible to write any Unicode code point either directly or with numeric escapes. This will be discussed in later sections.
Runes are printed with %c, or with %q if quoting is desired:
ascii := 'a' unicode := 'D' newline := '\n' fmt.Printf("%d %[1]c %[1]q\n", ascii) // "97 a 'a'" fmt.Printf("%d %[1]c %[1]q\n", unicode) // "22269 D 'D'" fmt.Printf("%d %[1]q\n", newline) // "10 '\n'"
Floating-Point Numbers¶
There are two sizes of floating-point numbers, whose properties are governed by the IEEE 754 standard (implemented by all modern CPUs). The limits of floating-point values can be found in the math package.
float32- The largest
float32is the constantmath.MaxFloat32, which is about3.4e38. - The smallest positive value is
1.4e-45.
- The largest
float64- The largest
float64is the constantmath.MaxFloat64, which is about1.8e308. - The smallest positive value is
4.9e-324.
- The largest
A float32 provides approximately six decimal digits of precision, whereas a float64 provides about 15 digits. float64 should be preferred for most purposes because float32 computations accumulate error rapidly if not careful; the smallest positive integer that cannot be exactly represented as a float32 is not large:
Floating-point numbers can be written literally using decimals. For example:
const e = 2.71828 // (approximately)
Digits may be omitted before the decimal point (e.g. .707) or after it (e.g. 1.). Very small or very large numbers are better written in scientific notation, with the letter e or E preceding the decimal exponent:
const Avogadro = 6.02214129e23 const Planck = 6.62606957e-34
Floating-point values can be printed with Printf's following verbs:
%g: it chooses the most compact representation that has adequate precision, i.e.%efor large exponents,%fotherwise%e(exponent): decimal point with exponent (scientific notation)%f: decimal point but no exponent
All three verbs allow field width and numeric precision to be controlled.
for x := 0; x < 8; x++ { fmt.Printf("x = %d e**x = %8.3f\n", x, math.Exp(float64(x))) }
The code above prints the powers of e with three decimal digits of precision, aligned in an eight-character field:
x = 0 e**x = 1.000 x = 1 e**x = 2.718 x = 2 e**x = 7.389 x = 3 e**x = 20.086 x = 4 e**x = 54.598 x = 5 e**x = 148.413 x = 6 e**x = 403.429 x = 7 e**x = 1096.633
Special values: +Inf, -Inf, and NaN *¶
In addition to mathematical functions, the math package has functions for creating and detecting the special values defined by IEEE 754:
- Positive and negative infinities, which represent numbers of excessive magnitude and the result of division by zero;
- NaN ("not a number"), the result of such mathematically dubious operations as
0/0orSqrt(-1).
var z float64 fmt.Println(z, -z, 1/z, -1/z, z/z) // "0 -0 +Inf -Inf NaN"
The function math.IsNaN tests whether its argument is a not-a-number value, and math.NaN returns such a value. It’s tempting to use NaN as a sentinel value in a numeric computation. Be careful when testing whether a specific computational result is equal to NaN: any comparison with NaN always yields false.
nan := math.NaN() fmt.Println(nan == nan, nan < nan, nan > nan) // "false false false"
If a function that returns a floating-point result might fail, it’s better to report the failure separately, like this:
func compute() (value float64, ok bool) { // ... if failed { return 0, false } return result, true }
[p58-60]
Complex Numbers¶
Go provides two sizes of complex numbers, complex64 and complex128, whose components are float32 and float64 respectively. The built-in function complex creates a complex number from its real and imaginary components, and the built-in real and imag functions extract those components:
var x complex128 = complex(1, 2) // 1+2i var y complex128 = complex(3, 4) // 3+4i fmt.Println(x*y) // "(-5+10i)" fmt.Println(real(x*y)) // "-5" fmt.Println(imag(x*y)) // "10"
If a floating-point literal or decimal integer literal is immediately followed by i, such as 3.141592i or 2i, it becomes an imaginary literal, denoting a complex number with a zero real component:
fmt.Println(1i * 1i) // "(-1+0i)", i$ = -1
Complex numbers use the rules for constant arithmetic; complex constants can be added to other constants. Therefore, complex numbers can be written naturally, like 1+2i or 2i+1. The declarations of x and y above can be simplified:
x := 1 + 2i y := 3 + 4i
Complex numbers may be compared for equality with == and !=. Two complex numbers are equal if their real parts are equal and their imaginary parts are equal. The math/cmplx package provides library functions for working with complex numbers, such as the complex square root and exponentiation functions.
fmt.Println(cmplx.Sqrt(-1)) // "(0+1i)"
[p61-63]
Booleans¶
A value of type bool, or boolean, has only two possible values, true and false.
- The conditions in
ifandforstatements are booleans - Comparison operators (e.g.
==,<>) produce a boolean result. - The unary operator
!is logical negation. For example,!trueisfalse, or,(!true==false)==true. - Redundant boolean expressions can be simplified, like
x==truetox.
Boolean values can be combined with the && (AND) and || (OR) operators, which have short-circuit behavior: if the answer is already determined by the value of the left operand, the right operand is not evaluated, making it safe to write expressions like this:
s != "" && s[0] == 'x'
where s[0] would panic if applied to an empty string.
Since && has higher precedence than || (mnemonic: && is boolean multiplication, || is boolean addition), no parentheses are required for conditions of this form:
if 'a' <= c && c <= 'z' || 'A' <= c && c <= 'Z' || '0' <= c && c <= '9' { // ...ASCII letter or digit... }
There is no implicit conversion from a boolean value to a numeric value like 0 or 1, or vice versa.
It might be worth writing conversion functions:
// btoi returns 1 if b is true and 0 if false. func btoi(b bool) int { if b { return 1 } return 0 } // itob reports whether i is non-zero. func itob(i int) bool { return i != 0 }
Strings¶
A string is an immutable sequence of bytes. Strings may contain arbitrary data, including bytes with value 0, but usually they contain human-readable text. Text strings are conventionally interpreted as UTF-8-encoded sequences of Unicode code points (runes).
The built-in len function returns the number of bytes (not runes) in a string, and the index operation s[i] retrieves the i-th byte of string s, where 0 ≤ i < len(s).
s := "hello, world" fmt.Println(len(s)) // "12" fmt.Println(s[0], s[7]) // "104 119" ('h' and 'w')
In the above code, s[0] and s[7] is of uint8 type.
Attempting to access a byte outside this range results in a panic:
c := s[len(s)] // panic: index out of range
The i-th byte of a string is not necessarily the i-th character of a string, because the UTF-8 encoding of a non-ASCII code point requires two or more bytes.
The substring operation *¶
The substring operation s[i:j] yields a new string consisting of the bytes of the original string starting at index i and continuing up to, but not including, the byte at index j. The result contains j-i bytes.
fmt.Println(s[0:5]) // "hello"
A panic results if either index is out of bounds or if j is less than i.
Either or both of the i and j operands may be omitted:
- If
iis omitted, it defaults to 0 (the start of the string) - If
jis omitted, it defaults tolen(s)(its end).
fmt.Println(s[:5]) // "hello" fmt.Println(s[7:]) // "world" fmt.Println(s[:]) // "hello, world"
String concatenation, comparison and immutability *¶
The + operator makes a new string by concatenating two strings:
fmt.Println("goodbye" + s[5:]) // "goodbye, world"
Strings may be compared with comparison operators (e.g. == and <); the comparison is done byte by byte, so the result is the natural lexicographic ordering.
String values are immutable: the byte sequence contained in a string value can never be changed.
s[0] = 'L' // compile error: cannot assign to s[0]
However, we can assign a new value to a string variable. += can be used to append one string to another:
s := "left foot" t := s s += ", right foot"
This does not modify the string that s originally held but causes s to hold the new string formed by the += statement; meanwhile, t still contains the old string.
Immutability means that it is safe for two copies of a string to share the same underlying memory, making it cheap to copy strings of any length. Similarly, a string s and a substring like s[7:] may safely share the same data, so the substring operation is also cheap. No new memory is allocated in either case. The following figure illustrates the arrangement of a string and two of its substrings sharing the same underlying byte array.
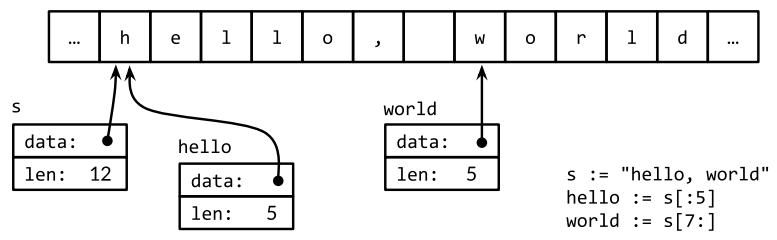
String Literals¶
A string value can be written as a string literal, a sequence of bytes enclosed in double quotes:
"Hello, 世界"
Go source files are always encoded in UTF-8 and Go text strings are conventionally interpreted as UTF-8. We can include Unicode code points in string literals.
Within a double-quoted string literal, escape sequences that begin with a backslash \ can be used to insert arbitrary byte values into the string. Some escapes handles ASCII control codes like newline, carriage return, and tab:
\a: "alert" or bell\b: backspace\f: form feed\n: newline\r: carriage return\t: tab\v: vertical tab\': single quote (only in the rune literal'\'')\": double quote (only within"..."literals)\\: backslash
Arbitrary bytes can also be included in literal strings using hexadecimal or octal escapes.
- A hexadecimal escape is written
\xhh, with exactly two hexadecimal digitsh(in upper or lower case). - An octal escape is written
\ooowith exactly three octal digitso(0 through 7) not exceeding\377(255 in decimal).
Both denote a single byte with the specified value.
Raw string literal *¶
A raw string literal is written `...`, using backquotes instead of double quotes. Within a raw string literal, no escape sequences are processed; the contents are taken literally, including backslashes and newlines, so a raw string literal may spread over several lines in the program source. The only processing is that carriage returns are deleted so that the value of the string is the same on all platforms, including those that conventionally put carriage returns in text files.
Raw string literals are a convenient way to write regular expressions, which tend to have lots of backslashes. They are also useful for HTML templates, JSON literals, and command usage messages, which often extend over multiple lines.
const GoUsage = `Go is a tool for managing Go source code. Usage: go command [arguments] ...`
Unicode¶
In early days, ASCII (short for American Standard Code for Information Interchange), or more precisely US-ASCII, uses 7 bits to represent 128 "characters": the upper- and lower-case letters of English, digits, and a variety of punctuation and device-control characters. With the growth of the Internet, data in various languages has become much more common. How to deal with this variety?
The answer is Unicode (unicode.org), which collects all of the characters in all of the world's writing systems, plus:
- Accents and other diacritical marks
- Control codes like tab and carriage return
- Plenty of esoterica
Each of these characters is assigned a standard number called a Unicode code point or, in Go terminology, a rune.
Unicode version 8 defines code points for over 120,000 characters in over 100 languages and scripts. In computer programs and data, the natural data type to hold a single rune is int32. This is what Go uses and is why it has the synonym rune for precisely this purpose.
A sequence of runes can be represented as a sequence of int32 values. In this representation, which is called UTF-32 or UCS-4, the encoding of each Unicode code point has the same size, 32 bits. This is simple and uniform, but it uses much more space than necessary since most computer-readable text is in ASCII, which requires only 8 bits or 1 byte per character. All the characters in widespread use still number fewer than 65,536, which would fit in 16 bits.
UTF-8¶
UTF-8 is a variable-length encoding of Unicode code points as bytes. UTF-8 was invented by Ken Thompson and Rob Pike, two of the creators of Go, and is now a Unicode standard. It uses between 1 and 4 bytes to represent each rune, but only 1 byte for ASCII characters, and only 2 or 3 bytes for most runes in common use. The high-order bits of the first byte of the encoding for a rune indicate how many bytes follow:
- A high-order
0indicates 7-bit ASCII, where each rune takes only 1 byte, so it is identical to conventional ASCII. - A high-order
110indicates that the rune takes 2 bytes; the second byte begins with 10. - Larger runes have analogous encodings.
| Encoding Format | Range | Description |
|---|---|---|
0xxxxxx |
runes 0−127 | (ASCII) |
11xxxxx 10xxxxxx |
128−2047 | (values <128 unused) |
110xxxx 10xxxxxx 10xxxxxx |
2048−65535 | (values <2048 unused) |
1110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
65536−0x10ffff | (other values unused) |
Although a variable-length encoding precludes direct indexing to access the n-th character of a string, UTF-8 has many desirable properties:
- The UTF-8 encoding is compact, compatible with ASCII, and self-synchronizing: it's possible to find the beginning of a character by backing up no more than three bytes.
- It's a prefix code, so it can be decoded from left to right without any ambiguity or lookahead. No rune’s encoding is a substring of any other, or even of a sequence of others, so you can search for a rune by just searching for its bytes, without worrying about the preceding context.
- The lexicographic byte order equals the Unicode code point order, so sorting UTF-8 works naturally.
- There are no embedded NUL (zero) bytes, which is convenient for programming languages that use NUL to terminate strings.
Go source files are always encoded in UTF-8, and UTF-8 is the preferred encoding for text strings manipulated by Go programs.
- The
unicodepackage provides functions for working with individual runes (such as distinguishing letters from numbers, or converting an uppercase letter to a lower-case one) - The
unicode/utf8package provides functions for encoding and decoding runes as bytes using UTF-8.
Many Unicode characters are hard to type on a keyboard or to distinguish visually from similar-looking ones; some are even invisible. Unicode escapes in Go string literals can be specified by their numeric code point value. There are two forms:
\uhhhh for a 16-bit value\Uhhhhhhhh for a 32-bit value
Each h is a hexadecimal digit, though the 32-bit form is used very infrequently. Each denotes the UTF-8 encoding of the specified code point. For example, the following string literals all represent the same six-byte string:
"世界" "\xe4\xb8\x96\xe7\x95\x8c" "\u4e16\u754c" "\U00004e16\U0000754c"
The three escape sequences above provide alternative notations for the first string, but the values they denote are identical. Unicode escapes may also be used in rune literals. These three rune literals are equivalent:
'世' '\u4e16' '\U00004e16'
A rune whose value is less than 256 may be written with a single hexadecimal escape, such as '\x41' for 'A', but for higher values, a \u or \U escape must be used. Consequently, '\xe4\xb8\x96' is not a legal rune literal, even though those three bytes are a valid UTF-8 encoding of a single code point.
Due to the properties of UTF-8, many string operations don't require decoding.
We can test whether one string contains another:
- As a prefix:
func HasPrefix(s, prefix string) bool { return len(s) >= len(prefix) && s[:len(prefix)] == prefix }
- As a suffix:
func HasSuffix(s, suffix string) bool { return len(s) >= len(suffix) && s[len(s)-len(suffix):] == suffix }
- A as a substring:
func Contains(s, substr string) bool { for i := 0; i < len(s); i++ { if HasPrefix(s[i:], substr) { return true } } return false }
These functions, which are drawn from the strings package, use the same logic for UTF-8-encoded text as for raw bytes. This is not true for other encodings.
If we care about the individual Unicode characters, we have to use other mechanisms. Consider the string from our very first example, "Hello, 世界", which includes two East Asian characters. The following figure illustrates its representation in memory.
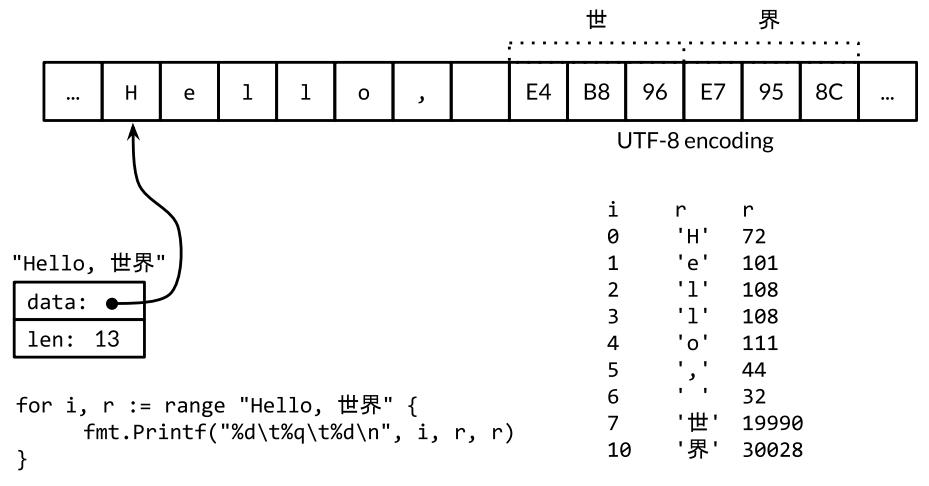
The string contains 13 bytes, but interpreted as UTF-8, it encodes only nine code points or runes:
import "unicode/utf8" s := "Hello, 世界" fmt.Println(len(s)) // "13" fmt.Println(utf8.RuneCountInString(s)) // "9"
The unicode/utf8 package provides the decoder to process those characters, with which we can use like this:
for i := 0; i < len(s); { r, size := utf8.DecodeRuneInString(s[i:]) fmt.Printf("%d\t%c\n", i, r) i += size }
Each call to DecodeRuneInString returns r, the rune itself, and size, the number of bytes occupied by the UTF-8 encoding of r. The size is used to update the byte index i of the next rune in the string.
Go’s range loop, when applied to a string, performs UTF-8 decoding implicitly. The output of the loop below is also shown in Figure 3.5; notice how the index jumps by more than 1 for each non-ASCII rune.
for i, r := range "Hello, 世界" { fmt.Printf("%d\t%q\t%d\n", i, r, r) }
We could use a simple range loop to count the number of runes in a string, like this:
n := 0 for _, _ = range s { n++ }
As with the other forms of range loop, we can omit the variables we don’t need:
n := 0 for range s { n++ }
The result of n is the same to that of utf8.RuneCountInString(s).
In Go, although it is a matter of convention that text strings are interpreted as UTF-8-encoded sequences of Unicode code points, it's a necessity for correct use of range loops on strings.
The replacement characters *¶
What happens if we range over a string containing arbitrary binary data or UTF-8 data containing errors?
Each time a UTF-8 decoder, whether explicit in a call to utf8.DecodeRuneInString or implicit in a range loop, consumes an unexpected input byte, it generates a special Unicode replacement character, '\uFFFD', which is usually printed as a white question mark inside a black hexagonal or diamond-like shape �. When a program encounters this rune value, it’s often a sign that some upstream part of the system that generated the string data has been careless in its treatment of text encodings.
UTF-8 is convenient as an interchange format, but within a program runes may be more convenient because they are of uniform size and are thus easily indexed in arrays and slices.
[]rune conversion *¶
A []rune conversion applied to a UTF-8-encoded string returns the sequence of Unicode code points that the string encodes:
// "program" in Japanese katakana s := "プログラム" fmt.Printf("% x\n", s) // "e3 83 97 e3 83 ad e3 82 b0 e3 83 a9 e3 83 a0" r := []rune(s) fmt.Printf("%x\n", r) // "[30d7 30ed 30b0 30e9 30e0]"
If a slice of runes is converted to a string, it produces the concatenation of the UTF-8 encodings of each rune:
fmt.Println(string(r)) // "プログラム"
Converting an integer value to a string interprets the integer as a rune value, and yields the UTF-8 representation of that rune:
fmt.Println(string(65)) // "A", not "65" fmt.Println(string(0x4eac)) // "京"
If the rune is invalid, the replacement character is substituted:
fmt.Println(string(1234567)) // "�"
Strings and Byte Slices¶
Four standard packages are particularly important for manipulating strings:
The strings package provides many functions for searching, replacing, comparing, trimming, splitting, and joining strings.
The bytes package has similar functions for manipulating slices of bytes, of type []byte, which share some properties with strings. Because strings are immutable, building up strings incrementally can involve a lot of allocation and copying. In such cases, it’s more efficient to use the bytes.Buffer type.
The strconv package provides functions for converting boolean, integer, and floating-point values to and from their string representations, and functions for quoting and unquoting strings.
The unicode package provides functions that use the Unicode standard categories for letters, digits, etc:
- Rune classifying functions like
IsDigit,IsLetter,IsUpper, andIsLower. Each function takes a single rune argument and returns a boolean. - Conversion functions like
ToUpperandToLowerconvert a rune into the given case if it is a letter.- The
stringspackage has similar functions, also calledToUpperandToLower, that return a new string with the specified transformation applied to each character of the original string.
- The
The basename function *¶
The basename function in the following example was inspired by the Unix shell utility basename. In our version, basename(s) removes any prefix of s that looks like a file system path with components separated by slashes, and it removes any suffix that looks like a file type:
fmt.Println(basename("a/b/c.go")) // "c" fmt.Println(basename("c.d.go")) // "c.d" fmt.Println(basename("abc")) // "abc"
The first version of basename does not use any libraries:
A simpler version uses the strings.LastIndex library function:
func basename(s string) string { slash := strings.LastIndex(s, "/") // -1 if "/" not found s = s[slash+1:] if dot := strings.LastIndex(s, "."); dot >= 0 { s = s[:dot] } return s }
The path and path/filepath packages *¶
The path and path/filepath packages provide a set of functions for manipulating hierarchical names.
- The
pathpackage works with slash-delimited paths on any platform. It shouldn’t be used for file names, but it is appropriate for other domains, like URL. - The
path/filepathpackage manipulates file names using the rules for the host platform, such as/foo/barfor POSIX orc:\foo\baron Microsoft Windows.
A substring example: comma *¶
The task is to take a string representation of an integer, such as "12345", and insert commas every three places, as in "12,345".
// comma inserts commas in a non-negative decimal integer string. func comma(s string) string { n := len(s) if n <= 3 { return s } return comma(s[:n-3]) + "," + s[n-3:] }
[p73]
A string contains an array of bytes that, once created, is immutable. By contrast, the elements of a byte slice can be freely modified.
Strings can be converted to byte slices and back again:
s := "abc" b := []byte(s) s2 := string(b)
- The
[]byte(s)conversion allocates a new byte array holding a copy of the bytes ofs, and yields a slice that references the entirety of that array. - The
string(b)conversion from byte slice back to string also makes a copy, to ensure immutability of the resulting strings2.
To avoid conversions and unnecessary memory allocation, many of the utility functions in the bytes package directly parallel their counterparts in the strings package. For example, the following functions are from strings:
func Contains(s, substr string) bool func Count(s, sep string) int func Fields(s string) []string func HasPrefix(s, prefix string) bool func Index(s, sep string) int func Join(a []string, sep string) string
and the corresponding ones from bytes:
func Contains(b, subslice []byte) bool func Count(s, sep []byte) int func Fields(s []byte) [][]byte func HasPrefix(s, prefix []byte) bool func Index(s, sep []byte) int func Join(s [][]byte, sep []byte) []byte
The only difference is that strings have been replaced by byte slices.
The bytes package provides the Buffer type for efficient manipulation of byte slices. A Buffer starts out empty but grows as data of types like string, byte, and []byte are written to it. A bytes.Buffer variable requires no initialization because its zero value is usable:
// intsToString is like fmt.Sprintf(values) but adds commas. func intsToString(values []int) string { var buf bytes.Buffer buf.WriteByte('[') for i, v := range values { if i > 0 { buf.WriteString(", ") } fmt.Fprintf(&buf, "%d", v) } buf.WriteByte(']') return buf.String() }
When appending the UTF-8 encoding of an arbitrary rune to a bytes.Buffer, it’s best to use bytes.Buffer’s WriteRune method, but WriteByte is fine for ASCII characters such as '[' and ']'.
The bytes.Buffer type is extremely versatile. Chapter 7 discusses how it may be used as a replacement for a file whenever an I/O function requires either of:
- A sink for bytes (
io.Writer) asFprintfdoes above. - A source of bytes (
io.Reader).
Conversions between Strings and Numbers¶
In addition to conversions between strings, runes, and bytes, it's often necessary to convert between numeric values and their string representations, which is done with functions from the strconv package.
To convert an integer to a string, there are two options:
fmt.Sprintfstrconv.Itoa("integer to ASCII"):
x := 123 y := fmt.Sprintf("%d", x) fmt.Println(y, strconv.Itoa(x)) // "123 123"
FormatInt and FormatUint can be used to format numbers in a different base:
fmt.Println(strconv.FormatInt(int64(x), 2)) // "1111011"
The fmt.Printf verbs %b, %d, %u, and %x are often more convenient than Format functions, especially if we want to include additional information besides the number:
s := fmt.Sprintf("x=%b", x) // "x=1111011"
To parse a string representing an integer, use the strconv functions Atoi or ParseInt, or ParseUint for unsigned integers:
x, err := strconv.Atoi("123") // x is an int y, err := strconv.ParseInt("123", 10, 64) // base 10, up to 64 bits
The third argument of ParseInt gives the size of the integer type that the result must fit into: the special value of 0 implies int. In any case, the type of the result y is always int64, which you can then convert to a smaller type.
fmt.Scanf can be used to parse input that consists of orderly mixtures of strings and numbers all on a single line, but it is inflexible, especially when handling incomplete or irregular input.
Constants¶
Constants are expressions whose value is known to the compiler and whose evaluation is guaranteed to occur at compile time, not at run time. The underlying type of every constant is a basic type: boolean, string, or number.
A const declaration defines named values that look syntactically like variables but whose value is constant, which prevents accidental changes during program execution.
const pi = 3.14159 // approximately; math.Pi is a better approximation
As with variables, a sequence of constants can appear in one declaration, appropriate for a group of related values:
const ( e = 2.71828 pi = 3.14159 )
Computations on constants can be evaluated at compile time, reducing the work necessary at run time and enabling other compiler optimizations. Errors ordinarily detected at run time can be reported at compile time when their operands are constants, such as:
- Integer division by zeros
- String indexing out of bounds
- Floating-point operation that would result in a non-finite value
The results of all arithmetic, logical, and comparison operations applied to constant operands are themselves constants, as are the results of conversions and calls to certain built-in functions such as len, cap, real, imag, complex, and unsafe.Sizeof.
Constant expressions may appear in types, specifically as the length of an array type:
const IPv4Len = 4 // parseIPv4 parses an IPv4 address (d.d.d.d). func parseIPv4(s string) IP { var p [IPv4Len]byte // ... }
A constant declaration may have a type and a value. In the absence of an explicit type, the type is inferred from the expression on the right-hand side. In the following, time.Duration is a named type whose underlying type is int64, and time.Minute is a constant of that type. Both of the constants declared below have the type time.Duration (revealed by %T):
const noDelay time.Duration = 0 const timeout = 5 * time.Minute fmt.Printf("%T %[1]v\n", noDelay) // "time.Duration 0" fmt.Printf("%T %[1]v\n", timeout) // "time.Duration 5m0s fmt.Printf("%T %[1]v\n", time.Minute) // "time.Duration 1m0s"
When a sequence of constants is declared as a group, the right-hand side expression may be omitted for all but the first of the group, implying that the previous expression and its type should be used again. For example:
const ( a = 1 b c = 2 d ) fmt.Println(a, b, c, d) // "1 1 2 2"
The Constant Generator iota¶
The constant generator iota can be used in a const declaration to create a sequence of related values; the value of iota begins at zero and increments by one for each item in the sequence.
The following example is from the time package, which defines named constants of type Weekday for the days of the week. This kind of types are often called enumerations, or enums for short.
type Weekday int const ( Sunday Weekday = iota Monday Tuesday Wednesday Thursday Friday Saturday )
This declares Sunday to be 0, Monday to be 1, and so on.
iota can also be used in more complex expression. The following example is from the net package where each of the lowest 5 bits of an unsigned integer is given a distinct name and boolean interpretation:
type Flags uint const ( FlagUp Flags = 1 << iota // is up FlagBroadcast // supports broadcast access capability FlagLoopback // is a loopback interface FlagPointToPoint // belongs to a point-to-point link FlagMulticast // supports multicast access capability )
As iota increments, each constant is assigned the value of 1 << iota, which evaluates to successive powers of two (each corresponding to a single bit). The functions in gopl.io/ch3/netflag/netflag.go test, set or clear bits of those constants.
The following declaration names the powers of 1024:
const ( _ = 1 << (10 * iota) KiB // 1024 MiB // 1048576 GiB // 1073741824 TiB // 1099511627776 (exceeds 1 << 32) PiB // 1125899906842624 EiB // 1152921504606846976 ZiB // 1180591620717411303424 (exceeds 1 << 64) YiB // 1208925819614629174706176 )
[p78]
Untyped Constants¶
Although a constant can have any of the basic data types (e.g. int, float64, time.Duration), many constants are not committed to a particular type. The compiler represents these uncommitted constants with much greater numeric precision than values of basic types, and arithmetic on them is more precise than machine arithmetic; you may assume at least 256 bits of precision. There are six flavors of these uncommitted constants
- Untyped boolean
- Untyped integer
- Untyped rune
- Untyped floating-point
- Untyped complex
- Untyped string
Untyped constants can retain higher precision and participate in many more expressions than committed constants without requiring conversions. For example, the values ZiB and YiB in the example above are too big to store in any integer variable, but they are legitimate constants that may be used in expressions like this one:
fmt.Println(YiB/ZiB) // "1024"
The floating-point constant math.Pi may be used wherever any floating-point or complex value is needed:
var x float32 = math.Pi var y float64 = math.Pi var z complex128 = math.Pi
If math.Pi had been committed to a specific type such as float64, the result would not be as precise, and type conversions would be required:
const Pi64 float64 = math.Pi var x float32 = float32(Pi64) var y float64 = Pi64 var z complex128 = complex128(Pi64)
For literals, syntax determines flavor. The literals in the table below all denote constants of the same value but different flavors:
| Literal | Flavor |
|---|---|
0 |
untyped integer |
0.0 |
untyped floating-point |
0i |
untyped complex |
'\u0000' |
untyped rune |
Similarly, true and false are untyped booleans and string literals are untyped strings.
/ may represent integer or floating-point division depending on its operands. Consequently, the choice of literal may affect the result of a constant division expression:
var f float64 = 212 fmt.Println((f - 32) * 5 / 9) // "100"; (f - 32) * 5 is a float64 fmt.Println(5 / 9 * (f - 32)) // "0"; 5/9 is an untyped integer, 0 fmt.Println(5.0 / 9.0 * (f - 32)) // "100"; 5.0/9.0 is an untyped float
Only constants can be untyped. The constant is implicitly converted to the type of the variable if either of the following happens:
- The untyped constant is assigned to a variable (first statement in the example below).
- The untyped constant appears on the right-hand side of a variable declaration with an explicit type (the other three statements in the example below).
For example:
var f float64 = 3 + 0i // untyped complex -> float64 f = 2 // untyped integer -> float64 f = 1e123 // untyped floating-point -> float64 f = 'a' // untyped rune -> float64
The statements above are equivalent to these:
var f float64 = float64(3 + 0i) f = float64(2) f = float64(1e123) f = float64('a')
Whether implicit or explicit, converting a constant from one type to another requires that the target type can represent the original value. Rounding is allowed for real and complex floating-point numbers:
const ( deadbeef = 0xdeadbeef // untyped int with value 3735928559 a = uint32(deadbeef) // uint32 with value 3735928559 b = float32(deadbeef) // float32 with value 3735928576 (rounded up) c = float64(deadbeef) // float64 with value 3735928559 (exact) d = int32(deadbeef) // compile error: constant overflows int32 e = float64(1e309) // compile error: constant overflows float64 f = uint(-1) // compile error: constant underflows uint )
In a variable declaration without an explicit type (including short variable declarations), the flavor of the untyped constant implicitly determines the default type of the variable. For example:
i := 0 // untyped integer; implicit int(0) r := '\000' // untyped rune; implicit rune('\000') f := 0.0 // untyped floating-point; implicit float64(0.0) c := 0i // untyped complex; implicit complex128(0i)
In the above example, the asymmetry should be noted: untyped integers are converted to int, whose size is not guaranteed, but untyped floating-point and complex numbers are converted to the explicitly sized types float64 and complex128. The language has no unsized float and complex types analogous to unsized int, because it is very difficult to write correct numerical algorithms without knowing the size of one’s floating-point data types.
To give the variable a different type, we must explicitly convert the untyped constant to the desired type or state the desired type in the variable declaration. For example:
var i = int8(0) var i int8 = 0
These defaults are particularly important when converting an untyped constant to an interface value (Chapter 7) since they determine its dynamic type.
fmt.Printf("%T\n", 0) // "int" fmt.Printf("%T\n", 0.0) // "float64" fmt.Printf("%T\n", 0i) // "complex128" fmt.Printf("%T\n", '\000') // "int32" (rune)
Doubts and Solution¶
Verbatim¶
p53 on bitwise binary operator &^¶
The
&^operator is bit clear (AND NOT): in the expressionz = x &^ y, each bit ofzis 0 if the corresponding bit ofyis 1; otherwise it equals the corresponding bit ofx.
Question: What does it mean?
Solution:
- Stack Overflow:
x &^ ymeans to get the bits that are inxAND NOT iny. See also bitwise operation examples. "BF"