Chapter 12. TCP: The Transmission Control Protocol (Preliminaries)¶
Introduction¶
[p579]
The protocols discussed so far do not include mechanisms for delivering data reliably; they may detect that erroneous data has been received, using a checksum or CRC, but they do not try very hard to repair errors:
- With IP and UDP, no error repair is done at all.
- With Ethernet and other protocols based on it, the protocol provides some number of retries and then gives up if it cannot succeed.
Information theory and coding theory¶
- Error-correcting codes (adding redundant bits so that the real information can be retrieved even if some bits are damaged) is one way to correct communications problems is one very important method for handling errors.
- Automatic Repeat Request (ARQ): which means "try sending again" until the information is finally received. This approach forms the basis for many communications protocols, including TCP.
ARQ and Retransmission¶
For a multihop communications channel, there are other problems besides packet bit errors:
- Problems that arise at an intermediate router
- Packet reordering
- Packet duplication
- Packet erasures (drops)
An error-correcting protocol designed for use over a multihop communications channel (such as IP) must cope with all of these problems.
Packet drops and bit errors¶
A straightforward method dealing with packet drops (and bit errors) is to resend the packet until it is received properly. This requires a way to determine:
- Whether the receiver has received the packet.
- Whether the packet it received was the same one the sender sent.
This is solved by using acknowledgment (ACK): the sender sends a packet and awaits an ACK. When the receiver receives the packet, it sends the ACK. When the sender receives the ACK, it sends another packet, and the process continues. Interesting questions to ask here are:
- How long should the sender (expect to) wait for an ACK?
- This is discussed in Chapter 14.
- What if the ACK is lost?
- If an ACK is dropped, the sender cannot distinguish this case from the case in which the original packet is dropped, so it simply sends the packet again. The receiver may receive two or more copies in that case, so it must be prepared to handle that situation
- What if the packet was received but had errors in it?
- Detecting errors is easiter than correcting errors. By using a form of checksum. When a receiver receives a packet containing an error, it refrains from sending an ACK. Eventually, the sender resends the packet, which ideally arrives undamaged.
Packet duplication¶
The receiver might receive duplicate copies of the packet. This problem is addressed using a sequence number. Every unique packet gets a new sequence number when it is sent at the source, and this sequence number is carried along in the packet itself. The receiver can use this number to determine whether it has already seen the packet and if so, discard it.
Efficiency¶
The protocol described so far is reliable but not very efficient. The sender injects a single packet into the communications path but then must stop until it hears the ACK. This protocol is therefore called "stop and wait". Its throughput performance (data sent on the network per unit time) is proportional to M/R where M is the packet size and R is the round-trip time (RTT), assuming no packets are lost or irreparably damaged in transit. For a fixed-size packet, as R goes up, the throughput goes down. If packets are lost or damaged, the situation is even worse: the "goodput" (useful amount of data transferred per unit time) can be considerably less than the throughput.
For a network that doesn’t damage or drop many packets, the cause for low throughput is usually that the network is not being kept busy. The situation is similar to using an assembly line where new work cannot enter the line until a complete product emerges. Most of the line goes idle. We could have more than one work unit in the line at a time. This is same for networks: if we could have more than one packet in the network, we would keep it "more busy", leading to higher throughput.
Allowing more than one packet to be in the network at a time:
- The sender must decide not only when to inject a packet into the network, but also how many. It also must figure out how to keep the timers when waiting for ACKs, and it must keep a copy of each packet not yet acknowledged in case retransmissions are necessary.
- The receiver needs to have a more sophisticated ACK mechanism: one that can distinguish which packets have been received and which have not.
- The receiver may need a more sophisticated buffering (packet storage) mechanism: one that allows it to hold "out-of-sequence" packets (those packets that have arrived earlier than those expected because of loss or reordering).
There are other issues:
- What if the receiver is slower than the sender? If the sender simply injects many packets at a very high rate, the receiver might just drop them because of processing or memory limitations. The same question can be asked about the routers in the middle.
- What if the network infrastructure cannot handle the rate of data the sender and receiver wish to use?
Windows of Packets and Sliding Windows¶
Assume each unique packet has a sequence number. We define a window of packets as the collection of packets (or their sequence numbers) that have been injected by the sender but not yet completely acknowledged (the sender has not received an ACK for them). We refer to the window size as the number of packets in the window.
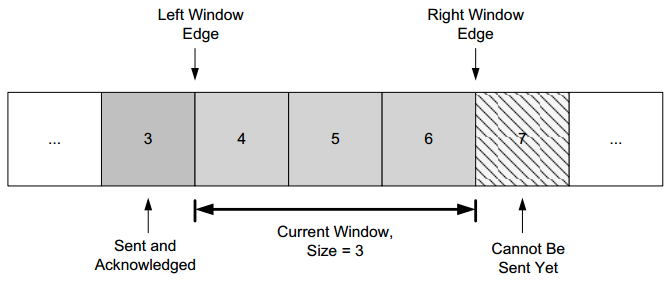
In the figure:
- Packet number 3 has already been sent and acknowledged, so the copy of it that the sender was keeping can now be released.
- Packet 7 is ready at the sender but not yet able to be sent because it is not yet "in" the window.
- When the sender receives an ACK for packet 4, the window "slides" to the right by one packet, meaning that the copy of packet 4 can be released and packet 7 can be sent.
This movement of the window gives rise to another name for this type of protocol, a sliding window protocol.
Typically, this window structure is kept at both the sender and the receiver.
- At the sender, it keeps track of what packets can be released, awaiting ACKs, and cannot yet be sent.
- At the receiver, it keeps track of:
- What packets have already been received and acknowledged,
- What packets are expected (and how much memory has been allocated to hold them),
- Which packets (even if received) will not be kept because of limited memory.
Although the window structure is convenient for keeping track of data as it flows between sender and receiver, it does not provide guidance as to how large the window should be, or what happens if the receiver or network cannot handle the sender’s data rate.
Variable Windows: Flow Control and Congestion Control¶
Flow control can handle problem that arises when a receiver is too slow relative to a sender, by forcing the sender to slow down when the receiver cannot keep up. It is usually handled in one of two ways:
- Rate-based flow control gives the sender a certain data rate allocation and ensures that data is never allowed to be sent at a rate that exceeds the allocation. This type of flow control is most appropriate for streaming applications and can be used with broadcast and multicast delivery (Chapter 9).
- Window-based flow control is the most popular approach when sliding windows are being used. In this approach, the window size is not fixed but is instead allowed to vary over time.
- Window advertisement, or simply a window update is a method for the receiver to signal the sender how large a window to use. This value is used by the sender (the receiver of the window advertisement) to adjust its window size.
- Logically, window update is separate from the ACKs we discussed previously, but in practice the window update and ACK are carried in a single packet, meaning that the sender tends to adjust the size of its window at the same time it slides it to the right.
If we consider the effect of changing the window size at the sender, it becomes clear how this achieves flow control. The sender is allowed to inject W packets into the network before it hears an ACK for any of them. If the sender and receiver are sufficiently fast, and the network loses no packets and has an infinite capacity, this means that the transfer rate is proportional to (SW/R) bits/s, where W is the window size, S is the packet size in bits, and R is the RTT. When the window advertisement from the receiver clamps the value of W at the sender, the sender’s overall rate can be limited so as to not overwhelm the receiver.
This approach works fine for protecting the receiver, but what about the network in between? We may have routers with limited memory between the sender and the receiver that have to contend with slow network links. When this happens, it is possible for the sender’s rate to exceed a router’s ability to keep up, leading to packet loss. This is addressed with a special form of flow control called congestion control.
Congestion control involves the sender slowing down so as to not overwhelm the network between itself and the receiver.
- Explicit signaling uses a window advertisement to signal the sender to slow down for the receiver.
- Implicit signaling: the sender guesses that it needs to slow down. It would involve deciding to slow down based on some other evidence.
The problem of congestion control in datagram-style networks, and more generally queuing theory to which it is closely related, has remained a major research topic for years, and it is unlikely to ever be solved completely for all circumstances. It is also not practical to discuss all the options and methods of performing flow control here. In Chapter 16 we will explore the particular congestion control technique used with TCP in more detail, along with a number of variants that have arisen over the years.
Setting the Retransmission Timeout¶
One of the most important performance issues is how long to wait before concluding that a packet has been lost and should be resent. That is, What should the retransmission timeout be? Intuitively, the amount of time the sender should wait before resending a packet is about the sum of the following times:
- The time to send the packet,
- The time for the receiver to process it and send an ACK,
- The time for the ACK to travel back to the sender,
- The time for the sender to process the ACK.
In practice, none of these times are known with certainty and any or all of them vary over time as additional load is added to or removed from the end hosts or routers.
Because it is not practical for the user to estimate all the times, a better strategy is to have the protocol implementation try to estimate them. This is called round-trip-time estimation and is a statistical process. The true RTT is likely to be close to the sample mean of a collection of samples of RTTs. This average naturally changes over time (it is not stationary), as the paths taken through the network may change.
[p584]
It would not be sensible to set the retransmission timer to be exactly equal to the mean estimator, as it is likely that many actual RTTs will be larger, thereby inducing unwanted retransmissions.
- The timeout should be set to something larger than the mean, but exactly what this relationship is (or even if the mean should be directly used) is not yet clear.
- Setting the timeout too large is also undesirable, as this leads back to letting the network go idle, reducing throughput.
This is further explored in Chapter 14.
Introduction to TCP¶
Our description of TCP starts in this chapter and continues in the next five chapters:
- Chapter 13: how a TCP connection is established and terminated.
- Chapter 14:
- How TCP estimates the per-connection RTT.
- How the retransmission timeout is set based on the above estimate.
- Chapter 15:
- Normal transfer of data (starting with "interactive" applications, such as chat).
- Window management and flow control, which apply to both interactive and "bulk" data flow applications (such as file transfer).
- Urgent mechanism of TCP, which allows a sender to mark certain data in the data stream as special.
- Chapter 16:
- Congestion control algorithms in TCP that help to reduce packet loss when the network is very busy.
- Modifications that have been proposed to increase throughput on fast networks or improve resiliency on lossy (e.g., wireless) networks.
- Chapter 17: how TCP keeps connections active even when no data is flowing.
The TCP Service Model¶
Even though TCP and UDP use the same network layer (IPv4 or IPv6), TCP provides a totally different service to the application layer from what UDP does. TCP provides a connection-oriented, reliable, byte stream service. The term connection-oriented means that the two applications using TCP must establish a TCP connection by contacting each other before they can exchange data. There are exactly two endpoints communicating with each other on a TCP connection; concepts such as broadcasting and multicasting (Chapter 9) are not applicable to TCP.
TCP provides a byte stream abstraction to applications that use it. Its consequence is that no record markers or message boundaries are automatically inserted by TCP (Chapter 1). A record marker corresponds to an indication of an application’s write extent. If the application on one end writes 10 bytes, followed by a write of 20 bytes, followed by a write of 50 bytes, the application at the other end of the connection cannot tell what size the individual writes were. For example, the other end may read the 80 bytes in four reads of 20 bytes at a time or in some other way. One end puts a stream of bytes into TCP, and the identical stream of bytes appears at the other end. Each endpoint individually chooses its read and write sizes.
TCP does not interpret the contents of the bytes in the byte stream at all. It has no idea if the data bytes being exchanged are binary data, ASCII characters, EBCDIC characters, or something else. The interpretation of this byte stream is up to the applications on each end of the connection. TCP supports the urgent mechanism mentioned before, although it is no longer recommended for use.
Reliability in TCP¶
TCP provides reliability using specific variations on the techniques just described.
- Packetization: TCP must convert a sending application’s stream of bytes into a set of packets that IP can carry, since it provides a byte stream interface.
- Repacketization: these packets contain sequence numbers, which in TCP actually represent the byte offsets of the first byte in each packet in the overall data stream rather than packet numbers. This allows packets to be of variable size during a transfer and may also allow them to be combined.
The application data is broken into what TCP considers the best-size chunks to send, typically fitting each segment into a single IP-layer datagram that will not be fragmented. This is different from UDP, where each write by the application usually generates a UDP datagram of that size (plus headers). The chunk passed by TCP to IP is called a segment. Chapter 15 discusses how TCP decides what size a segment should be.
TCP Header and Encapsulation¶
TCP is encapsulated in IP datagrams as shown the figure below:
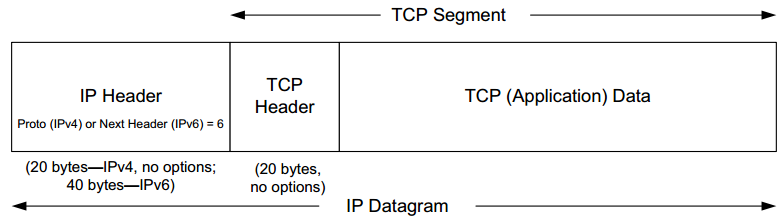
The TCP header (show in the figure below) is considerably more complicated than the UDP header (Chapter 10). This is not very surprising, as TCP is a significantly more complicated protocol that must keep each end of the connection informed (synchronized) about the current state.

Each TCP header contains the source and destination port number. The source and destination port number, along with the source and destination IP addresses in the IP header, uniquely identify each connection.
The combination of an IP address and a port number is sometimes called an endpoint or socket in the TCP literature. The term "socket" appeared in [RFC0793] and was ultimately adopted as the name of the Berkeley-derived programming interface for network communications (called "Berkeley sockets"). It is a pair of sockets or endpoints (the 4-tuple consisting of the client IP address, client port number, server IP address, and server port number) that uniquely identifies each TCP connection. This fact will become important when we look at how a TCP server can communicate with multiple clients (Chapter 13).
Sequence Number and Acknowledgment Number fields *¶
- The Sequence Number field identifies the byte in the stream of data from the sending TCP to the receiving TCP that the first byte of data in the containing segment represents.
- If we consider the stream of bytes flowing in one direction between two applications, TCP numbers each byte with a sequence number.
- This sequence number is a 32-bit unsigned number that wraps back around to 0 after reaching (232) − 1.
- The Acknowledgment Number field (also called the ACK Number or ACK field for short) contains the next sequence number that the sender of the acknowledgment expects to receive. This is therefore the sequence number of the last successfully received byte of data plus 1.
- This field is valid only if the ACK bit field is on, which it usually is for all but initial and closing segments.
- Sending an ACK costs nothing more than sending any other TCP segment because the 32-bit ACK Number field is always part of the header, as is the ACK bit field.
When a new connection is being established, the SYN bit field is turned on in the first segment sent from client to server. Such segments are called SYN segments, or simply SYNs. The Sequence Number field contains the first sequence number to be used on that direction of the connection for subsequent sequence numbers and in returning ACK numbers. This number is not 0 or 1 but instead is another number, often randomly chosen, called the initial sequence number (ISN). The reason for the ISN not being 0 or 1 is a security measure and will be discussed in Chapter 13. The sequence number of the first byte of data sent on this direction of the connection is the ISN plus 1 because the SYN bit field consumes one sequence number. Consuming a sequence number also implies reliable delivery using retransmission (discussed later). Thus, SYNs and application bytes (and FINs) are reliably delivered. ACKs, which do not consume sequence numbers, are not.
TCP can be described as "a sliding window protocol with cumulative positive acknowledgments". The ACK Number field is constructed to indicate the largest byte received in order at the receiver (plus 1). For example, if bytes 1–1024 are received OK, and the next segment contains bytes 2049–3072, the receiver cannot use the regular ACK Number field to signal the sender that it received this new segment. Modern TCPs, however, have a selective acknowledgment (SACK) option that allows the receiver to indicate to the sender out-of-order data it has received correctly. When paired with a TCP sender capable of selective repeat, a significant performance benefit may be realized [FF96]. Chapter 14 discusses how TCP uses duplicate acknowledgments (multiple segments with the same ACK field) to help with its congestion control and error control procedures
Other fields in the TCP header *¶
- The Header Length field gives the length of the header in 32-bit words. This is required because the length of the Options field is variable.
- With a 4-bit field, TCP is limited to a 60-byte header.
- Without options, the size is 20 bytes.
Currently eight bit fields are defined for the TCP header, although some older implementations understand only the last six of them ([RFC3540], an experimental RFC, also defines the least significant of the Resv bits as a nonce sum (NS)). One or more of them can be turned on at the same time. Their use are briefly mentioned here and detailed in later chapters:
- CWR. Congestion Window Reduced (the sender reduced its sending rate); see Chapter 16.
- ECE. ECN Echo (the sender received an earlier congestion notification); see Chapter 16.
- URG. Urgent (the Urgent Pointer field is valid; rarely used); see Chapter 15.
- ACK. Acknowledgment (the Acknowledgment Number field is valid; always on after a connection is established); see Chapters 13 and 15.
- PSH. Push (the receiver should pass this data to the application as soon as possible; not reliably implemented or used); see Chapter 15.
- RST. Reset the connection (connection abort, usually because of an error); see Chapter 13.
- SYN. Synchronize sequence numbers to initiate a connection; see Chapter 13.
- FIN. The sender of the segment is finished sending data to its peer; see Chapter 13.
Remaining fields:
- Window Size field. TCP’s flow control is provided by each end advertising a window size using the Window Size field. This is the number of bytes, starting with the one specified by the ACK number, that the receiver is willing to accept. This is a 16-bit field, limiting the window to 65,535 bytes, and thereby limiting TCP’s throughput performance. Chapter 15 discusses the Window Scale option that allows this value to be scaled, providing much larger windows and improved performance for high-speed and long-delay networks.
- The TCP Checksum field covers the TCP header and data and some fields in the IP header, using a pseudo-header computation similar to the one used with ICMPv6 and UDP discussed in Chapters 8 and Chapter 10. It is mandatory for this field to be calculated and stored by the sender, and then verified by the receiver. The TCP checksum is calculated with the same algorithm as the IP, ICMP, and UDP ("Internet") checksums.
- The Urgent Pointer field is valid only if the URG bit field is set. This "pointer" is a positive offset that must be added to the Sequence Number field of the segment to yield the sequence number of the last byte of urgent data. TCP’s urgent mechanism is a way for the sender to provide specially marked data to the other end.
- The most common Option field is the Maximum Segment Size option, called the MSS. Each end of a connection normally specifies this option on the first segment it sends (the ones with the SYN bit field set to establish the connection). The MSS option specifies the maximum-size segment that the sender of the option is willing to receive in the reverse direction. The MSS option is detailed in Chapter 13 and some of the other TCP options in Chapters 14 and Chapter 15.
- Other common options include SACK, Timestamp, and Window Scale.
TCP segments without data *¶
In Figure 12-2, the data portion of the TCP segment is optional. The TCP segment without data may be one of the following cases:
- Connection establishment and termination. When a connection is established, and when a connection is terminated, segments are exchanged that contain only the TCP header (with or without options) but no data.
- Acknowledgment. A header without any data is also used to acknowledge received data, if there is no data to be transmitted in that direction (called a pure ACK)
- Window update notifies the communication peer of a change in the window size.
- There are also some cases resulting from timeouts when a segment can be sent without any data.
Summary¶
The problem of providing reliable communications over lossy communication channels has been studied for years. The two primary methods for dealing with errors include error-correcting codes and data retransmission. The protocols using retransmissions must also handle data loss, usually by setting a timer, and must also arrange some way for the receiver to signal the sender what it has received. Deciding how long to wait for an ACK can be tricky, as the appropriate time may change as network routing or load on the end systems varies. Modern protocols estimate the round-trip time and set the retransmission timer based on some function of these measurements.
Except for setting the retransmission timer, retransmission protocols are simple when only one packet may be in the network at one time, but they perform poorly for networks where the delay is high. To be more efficient, multiple packets must be injected into the network before an ACK is received. This approach is more efficient but also more complex. A typical approach to managing the complexity is to use sliding windows, whereby packets are marked with sequence numbers, and the window size bounds the number of such packets. When the window size varies based on either feedback from the receiver or other signals (such as dropped packets), both flow control and congestion control can be achieved.
TCP provides a reliable, connection-oriented, byte stream, transport-layer service built using many of these techniques. We looked briefly at all of the fields in the TCP header, noting that most of them are directly related to these abstract concepts in reliable delivery. We will examine them in detail in the chapters that follow. TCP packetizes the application data into segments, sets a timeout anytime it sends data, acknowledges data received by the other end, reorders out-of-order data, discards duplicate data, provides end-to-end flow control, and calculates and verifies a mandatory end-to-end checksum. It is the most widely used protocol on the Internet. It is used by most of the popular applications, such as HTTP, SSH/TLS, NetBIOS (NBT—NetBIOS over TCP), Telnet, FTP, and electronic mail (SMTP). Many distributed file-sharing applications (e.g., BitTorrent, Shareaza) also use TCP.
Doubts and Solutions¶
Verbatim¶
p589 on SYN segments:
Consuming a sequence number also implies reliable delivery using retransmission (discussed later). Thus, SYNs and application bytes (and FINs) are reliably delivered. ACKs, which do not consume sequence numbers, are not.
Why?