Chapter 7. Firewalls and Network Address Translation (NAT)¶
Perhaps ironically, the development and eventual widespread use of NAT has contributed to significantly slow the adoption of IPv6. TCPv1
Many security problems (attacks) were caused by bugs or unplanned protocol operations in the software implementations of Internet hosts. Fixing the problem would have required a way to control the Internet traffic to which the end hosts were exposed. Today, this is provided by a firewall, a type of router that restricts the types of traffic it forwards. [p299]
As firewalls are being deployed, another problem was becoming important: the number of available IPv4 addresses was diminishing, with a threat of exhaustion. One of the most important mechanisms developed to deal with this, aside from IPv6, is called Network Address Translation (NAT). With NAT, Internet addresses need not be globally unique, but can be reused in different parts of the Internet, called address realms. This greatly eased the problem of address exhaustion.
Firewalls¶
Given the enormous management problems associated with trying to keep end system software up-to-date and bug-free, the focus of resisting attacks expanded
- From: securing end systems,
- To: restricting the Internet traffic allowed to flow to end systems by filtering out some traffic using firewalls.
Today, several different types of firewalls have evolved.
The two major types of firewalls commonly used include proxy firewalls and packet-filtering firewalls. The main difference between them is the layer in the protocol stack at which they operate, and consequently the way IP addresses and port numbers are used. The packet-filtering firewall is an Internet router that drops datagrams that (fail to) meet specific criteria. The proxy firewall operates as a multihomed server host from the viewpoint of an Internet client. That is, it is the endpoint of TCP and UDP transport associations; it does not typically route IP datagrams at the IP protocol layer.
Packet-Filtering Firewalls¶
Packet-filtering firewalls act as Internet routers and filter (drop) some traffic. They can generally be configured to discard or forward packets whose headers meet (or fail to meet) certain criteria, called filters.
Popular filters involve:
- Undesired IP addresses or options,
- Types of ICMP messages,
- Various UDP or TCP services, based on the port numbers contained in each packet.
Stateless and stateful:
- Stateless firewalls treat each datagram individually.
- Stateful firewalls are able associate packets with either previous or future packets to make inferences about datagrams or streams.
[p300]
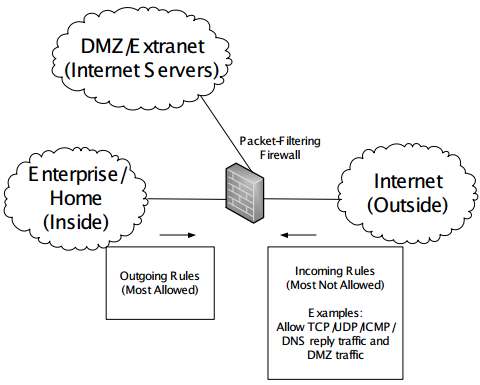
A typical packet-filtering firewall is shown below.
In this figure
- The firewall is an Internet router with three network interfaces:
- "inside"
- "outside"
- "DMZ"
- The DMZ subnet provides access to an extranet or DMZ where servers are deployed for Internet users to access.
- Network administrators install filters or access control lists (ACLs, basically policy lists indicating what types of packets to discard or forward) in the firewall.
- Typically, these filters conservatively block traffic from the outside that may be harmful and liberally allow traffic to travel from inside to outside.
Proxy Firewalls¶
Proxy firewalls are not really Internet routers. They are essentially hosts running one or more application-layer gateways (ALGs), hosts with more than one network interface that relay traffic of certain types between one connection/association and another at the application layer.
The figure below illustrates a proxy firewall:
- Clients on the inside of the firewall are usually configured in a special way to associate (or connect) with the proxy instead of the actual end host providing the desired service.
- The firewalls act as multihomed hosts with their IP forwarding capability typically disabled.
- As with packet-filtering firewalls, a common configuration is to have an "outside" interface assigned a globally routable IP address and for its "inner" interface to be configured with a private IP address. Thus, proxy firewalls support the use of private address realms.
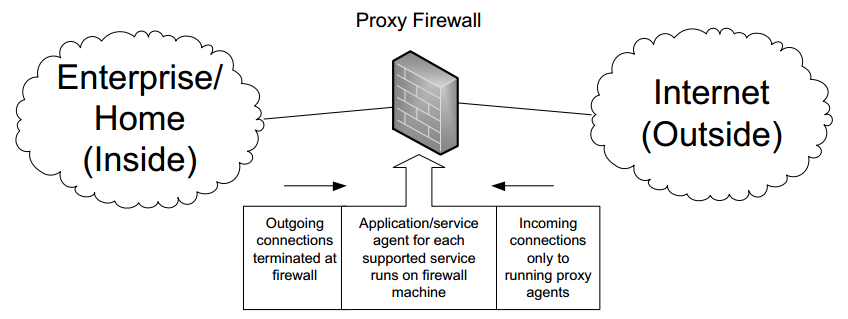
This type of firewall can be quite secure at the cost of brittleness and lack of flexibility:
- Since this style of firewall must contain a proxy for each transport-layer service, any new services to be used must have a corresponding proxy installed and operated for connectivity to take place through the proxy.
- Each client must be configured to find the proxy, for example using the Web Proxy Auto-Discovery Protocol (WPAD), although there are some alternatives: capturing proxies that catch all traffic of a certain type regardless of destination address).
- Significant intervention is required from network operators to support additional services.
The two most common forms of proxy firewalls are HTTP proxy firewalls and SOCKS firewalls.
- HTTP proxy firewalls, also called Web proxies, work only for the HTTP and HTTPS (Web) protocols.
- These proxies act as Web servers for internal clients and as Web clients when accessing external Web sites.
- Such proxies often also operate as Web caches. These caches save copies of Web pages so that subsequent accesses can be served directly from the cache instead of from the originating Internet Web server. Doing so can reduce latency to display Web pages and improve the experience of users accessing the Web.
- Some Web proxies are also used as content filters, which attempt to block access to certain Web sites based on a “blacklist” of prohibited sites. Conversely, tunneling proxy servers are available on the Internet. These servers (e.g., psiphon, CGIProxy) essentially perform the opposite function: to allow users to avoid being blocked by content filters.
- SOCKS firewalls uses the SOCKS protocol, which is more generic than HTTP for proxy access and is applicable to more services than just the Web. Two versions of SOCKS are currently in use: version 4 (SOCKS5) and version 5 (SOCKS5). Version 4 provides the basic support for proxy traversal, and version 5 adds strong authentication, UDP traversal, and IPv6 addressing.
- To use a SOCKS proxy, an application must be written to use SOCKS (it must be "socksified") and configured to know the location and version of the SOCKS proxy. Then the client uses the SOCKS protocol to request the proxy to perform network connections and, optionally, DNS lookups.
Network Address Translation (NAT)¶
NAT is a mechanism that allows the same sets of IP addresses to be reused in different parts of the Internet. With NAT as a common use, all incoming and outgoing traffic passes through a single NAT device that partitions the inside (private) address realm from the global Internet address realm, all the internal systems can be provided Internet connectivity as clients using locally assigned, private IP addresses. [p303]
NAT was introduced to solve two problems: address depletion and concerns regarding the scalability of routing. NAT was initially suggested as a stopgap, temporary measure to be used until the deployment of some protocol with a larger number of addresses (IPv6) became widespread. Routing scalability was being tackled with the development of Classless Inter-Domain Routing (CIDR, Chapter 2)
NAT is popular because:
- It reduces the need for globally routable Internet addresses
- It offers some degree of natural firewall capability and requires little configuration.
Perhaps ironically, the development and eventual widespread use of NAT has contributed to significantly slow the adoption of IPv6. Among its other benefits, IPv6 was intended to make NAT unnecessary.
NAT has several drawbacks:
- Offering Internet-accessible services from the private side requires special configuration because privately addressed systems are not directly reachable from the Internet.
- Every packet in both directions of a connection or association must pass through the same NAT, because the NAT must actively rewrite the addressing information in each packet.
- NATs require connection state on a per-association (or per-connection) basis and must operate across multiple protocol layers, unlike conventional routers. Modifying an address at the IP layer also requires modifying checksums at the transport layer (see Chapters 10 and Chatper 13 regarding the pseudoheader checksum)
- Some applications protocols, especially those that send IP addressing information inside the application-layer payload, such as File Transfer Protocol (FTP) and Session Initiation Protocol (SIP), require a special application-layer gateway function that rewrites the application content in order to work unmodified with NAT or other NAT traversal methods that allow the applications to determine how to work with the specific NAT they are using.
Despite its shortcomings, NATs are very widely used, and most network routers support it; NAT supports the basic protocols (e.g., e-mail, Web browsing) that are needed by millions of client systems accessing the Internet every day.
A NAT works by rewriting the identifying information in packets transiting through a router. Most commonly NAT involves rewriting the source IP address of packets as they are forwarded in one direction and the destination IP addresses of packets traveling in the reverse direction. This allows the source IP address in outgoing packets to become one of the NAT router’s Internet-facing interfaces instead of the originating host’s. Thus, to a host on the Internet, packets coming from any of the hosts on the privately addressed side of the NAT appear to be coming from a globally routable IP address of the NAT router.
Most NATs perform both translation and packet filtering, and the packet-filtering criteria depend on the dynamics of the NAT state. The choice of packet-filtering policy may have a different granularity. For example, the treatment of unsolicited packets (those not associated with packets originating from behind the NAT) received by the NAT may depend on source and destination IP address and/or source and destination port number. [p305]
Traditional NAT: Basic NAT and NAPT¶
Traditional NAT includes both:
- Basic NAT. It performs rewriting of IP addresses only: a private address is rewritten to be a public address, often from a pool or range of public addresses supplied. This type of NAT is not the most popular because it does not help to dramatically reduce the need for (globally routable) IP addresses.
- Network Address Port Translation (NAPT), also known as IP masquerading. It uses transport-layer identifiers (i.e., ports for TCP and UDP, query identifiers for ICMP) to differentiate which host on the private side of the NAT is associated with a particular packet. This allows a large number of internal hosts to access the Internet simultaneously using a limited number of public addresses, often only a single one.
See the following figure for the distinction between basic NAT and NAPT:

The addresses used in a private addressing realm "behind" (or "inside") a NAT are not enforced by anyone other than the local network administrator. It is possible and acceptable for a private realm to make use of global address space. However, local systems in the private realm would most likely be unable to reach the public systems using the same addresses because the close proximity of the local systems would effectively "mask" the visibility of the farther-away systems using the same addresses. To avoid this, three IPv4 address ranges are reserved for use with private addressing realms: 10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16, which are often used as default values for address pools in embedded DHCP servers
NAT provides some degree of security, similar to a firewall [p306]:
- By default, systems on the private side (using private addresses) of the NAT cannot be reached from the Internet.
- A common policy allows almost all outgoing and returning traffic (associated with outgoing traffic) to pass through the NAT but blocks almost all incoming new connection requests. This behavior inhibits "probing" attacks that attempt to ascertain which IP addresses have active hosts available to exploit.
- A NAT (especially a NAPT) "hides" the number and configuration of internal addresses from the outside. NAT helps by providing topology hiding.
The following subsections discusses how NAT behaves with each major transport protocol and how it may be used in mixed IPv4/IPv6 environments. [p306]
NAT and TCP¶
When a TCP connection starts, an "active opener" or client usually sends a synchronization (SYN) packet to a "passive opener" or server. The server responds with its own SYN packet, which also includes an acknowledgment (ACK) of the client’s SYN. The client then responds with an ACK to the server. This “three-way handshake” establishes the connection. A similar exchange with finish (FIN) packets is used to gracefully close a connection. The connection can also be forcefully closed right away using a reset (RST) packet. The behavioral requirements for traditional NAT with TCP relate primarily to the TCP three-way handshake.
Referring to the figure below, consider a TCP connection initiated by the wireless client at 10.0.0.126 destined for the Web server on the host www.isoc.org (IPv4 address 212.110.167.157). With the format "(source IP:source port; destination IP:destination port)", the packet initiating the connection on the private segment might be addressed as (10.0.0.126:9200; 212.110.167.157:80).
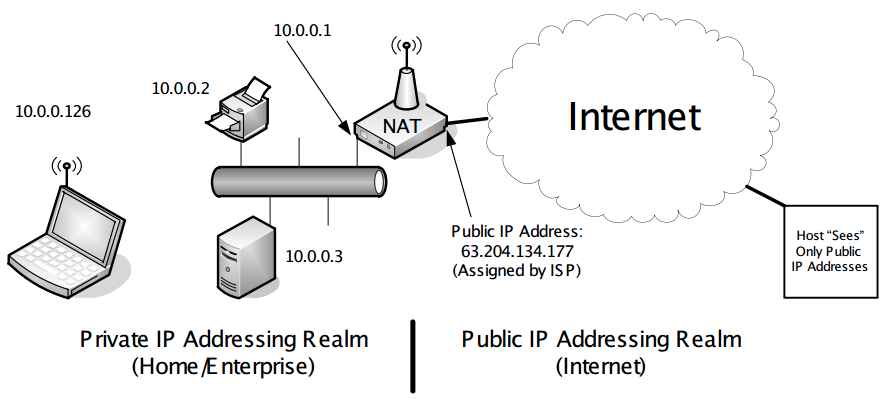
[p307]
- The NAT receives the first incoming packet from the client and notices it is a new connection (SYN bit in the TCP header is turned on).
- It modifies the source IP address to the routable IP address of the NAT router’s external interface. Thus, when the NAT forwards this packet, the addressing is (63.204.134.177:9200; 212.110.167.157:80).
- It creates a NAT session, which is internal state to remember that a new connection is being handled by the NAT. This state includes an entry, called a NAT mapping, containing the source port number and IP address of the client.
- The server replies to the endpoint (63.204.134.177:9200), the external NAT address, using the port number chosen initially by the client. This behavior is called port preservation. By matching the destination port number on the received datagram against the NAT mapping, the NAT ascertains the internal IP address of the client that made the initial request. The NAT rewrites the response packet from (212.110.167.157:80; 63.204.134.177:9200) to (212.110.167.157:80; 10.0.0.126:9200) and forwards it.
- The client then receives a response to its request and is now connected to the server.
Session state is removed if FINs are exchanged. The NAT must also remove "dead" mappings (identified by lack of traffic or RST) that are left stale in the NAT's memory, such when a client host is simply turned off.
Most NATs include a simplified TCP connection establishment procedures and can distinguish between connection success and failure:
- A connection timer is activated when an outgoing SYN segment is observed, and if no ACK is seen before the timer expires, the session state is cleared.
- A session timer is created, with a longer timeout (hours), after an ACK does arrives and the connection timer is canceled.
- The NAT may send an additional packet to the internal endpoint to doublecheck if the session is indeed dead (called probing). If it receives an ACK, the NAT realizes that the connection is still active, resets the session timer, and does not delete the session. If it receives either no response (after a close timer has expired) or an RST segment, the connection has gone dead, and the state is cleared.
A TCP connection can be configured to send "keepalive" packets (Chapter 17), and the default rate is one packet every 2 hours, if enabled. Otherwise, a TCP connection can remain established indefinitely. While a connection is being set up or cleared, however, the maximum idle time is 4 minutes. Consequently, [RFC5382] requires (REQ-5) that a NAT wait at least 2 hours and 4 minutes before concluding that an established connection is dead and at least 4 minutes before concluding that a partially opened or closed connection is dead.
There are tricky problems for TCP NAT. [p308] See Doubts and Solutions
NAT and UDP¶
Besides issues when performing NAT on TCP, the NAT on UDP has other issues due to:
- UDP has no connection establishment and clearing procedures as in TCP.
- There are no indicators such as the SYN, FIN, and RST bits to indicate that a session is being created or destroyed.
- An association may not be completely clear: UDP does not use a 4-tuple to identify a connection like TCP; it can rely on only the two endpoint address/port number combinations.
To handle these issues, UDP NATs use a mapping timer to clear NAT state if a binding has not been used "recently". The "recently" may mean different values. [RFC4787] requires the timer to be at least 2 minutes and recommends that it be 5 minutes. Timers can be refreshed when packets travel from the inside to the outside of the NAT (NAT outbound refresh behavior). [p309]
With IP fragmentation, an IP fragment other than the first one does not contain the port number information needed by NAPT to operate properly. This also applies to TCP and ICMP. Thus, fragments cannot be handled properly by simple NATs or NAPTs. [p309]
NAT and Other Transport Protocols (DCCP, SCTP)¶
- The Datagram Congestion Control Protocol (DCCP) [RFC4340] provides a congestion-controlled datagram service.
- The Stream Control Transmission Protocol (SCTP) [RFC4960] provides a reliable messaging service that can accommodate hosts with multiple addresses.
NAT and ICMP¶
The Internet Control Message Protocol (ICMP) provides status information about IP packets and can also be used for making certain measurements and gathering information about the state of the network.
ICMP has two categories of messages: informational and error: [p310]
- Error messages contain a (partial or full) copy of the IP packet that induced the error condition. They are sent from the point where an error was detected, often in the middle of the network, to the original sender.
- When an ICMP error message passes through a NAT, the IP addresses in the included "offending datagram" need to be rewritten by the NAT in order for them to make sense to the end client (called ICMP fix-up).
- Informational messages include a Query ID field that is handled much like port numbers for TCP or UDP.
- NAT handling these types of messages can recognize outgoing informational requests and set a timer in anticipation of a returning response.
NAT and Tunneled Packets¶
When tunneled packets (Chapter 3) are to be sent through a NATs, not only must a NAT rewrite the IP header, but it may also have to rewrite the headers or payloads of other packets that are encapsulated in them. One example of this is the Generic Routing Encapsulation (GRE) header used with the Point-to-Point Tunneling Protocol (PPTP). [p310]
NAT and Multicast¶
NATs can be configured to support multicast traffic (Chapter 9), although this is rare. [p310]
NAT and IPv6¶
There is staunch resistance to supporting the use of NAT with IPv6 based on the idea that saving address space is unnecessary with IPv6 and that other desirable NAT features (firewall-like functionality, topology hiding, and privacy) can be better achieved using Local Network Protection (LNP) [RFC4864]. LNP represents a collection of techniques with IPv6 that match or exceed the properties of NATs.
Aside from its packet-filtering properties, NAT supports the coexistence of multiple address realms and thereby helps to avoid the problem of a site having to change its IP addresses when it switches ISPs. [p310-311]
Address and Port Translation Behavior¶
One of the primary goals of the BEHAVE working group in IETF was to clarify the common behaviors and set guidelines. [p311]
See the following figure as a generic NAT mapping example:
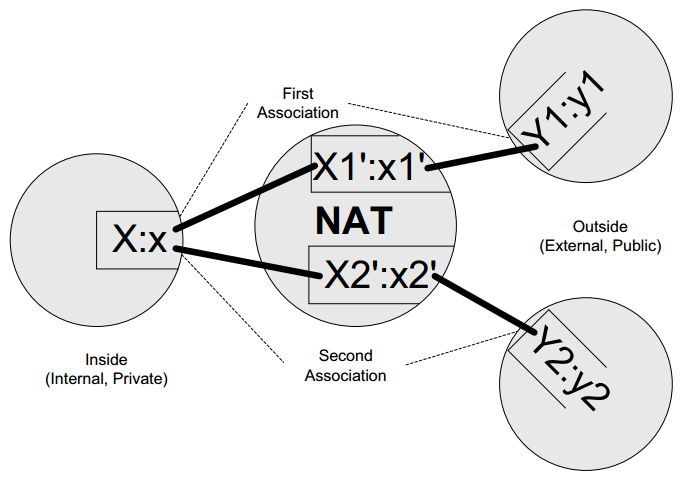
In this figure:
- The notation X:x indicates that a host in the private addressing realm (inside host) uses IP address X with port number x (for ICMP, the query ID is used instead of the port number). The IP address X is a private IPv4 address.
- To reach the remote address/port combination Y:y, the NAT establishes a mapping using an external (globally routable) address X1′ and port number x1′. Assuming that the internal host contacts Y1:y1 followed by Y2:y2, the NAT establishes mappings X1′:x1′ and X2′:x2′, respectively.
- In most cases, X1′ equals X2′ because most sites use only a single globally routable IP address.
- The mapping is said to be reused if x1′ equals x2′. If x1′ and x2′ equal x, the NAT implements port preservation, as mentioned earlier. In some cases, port preservation is not possible, so the NAT must deal with port collisions as suggested by Figure 7-4.
A NAT’s address and port behavior is characterized by what its mappings depend on. The inside host uses IP address:port X:x to contact Y1:y1 and then Y2:y2. The address and port used by the NAT for these associations are X1′:x1′ and X2′:x2′, respectively.
- If X1′:x1′ equals X2′:x2′ for any Y1:y1 or Y2:y2, the NAT has endpoint-independent mappings.
- If X1′:x1′ equals X2′:x2′ if and only if Y1 equals Y2, the NAT has address-dependent mappings.
- If X1′:x1′ equals X2′:x2′ if and only if Y1:y1 equals Y2:y2, the NAT has address and port-dependent mappings.
A NAT with multiple external addresses (i.e., where X1′ may not equal X2′) has an address pooling behavior of arbitrary if the outside address is chosen without regard to inside or outside address. Alternatively, it may have a pooling behavior of paired, in which case the same X1 is used for any association with Y1.
The figure above and the table below summarize the various NAT port and address behaviors based on definitions from [RFC4787]. The table also gives filtering behaviors that use similar terminology.
For all common transports, including TCP and UDP, the required NAT address- and port-handling behavior is endpoint-independent. The purpose of this requirement is to help applications that attempt to determine the external addresses used for their traffic to work more reliably. This is detailed in NAT traversal.
| Behavior Name | Translation Behavior | Filtering Behavior |
|---|---|---|
| Endpoint-independent | X1′:x1′ = X2′:x2′ for all Y2:y2 (required) | Allows any packets for X1:x1 as long as any X1′:x1′ exists (recommended for greatest transparency) |
| Address-dependent | X1′:x1′ = X2′:x2′ iff Y1 = Y2 | Allows packets for X1:x1 from Y1:y1 as long as X1 has previously contacted Y1 (recommended for more stringent filtering) |
| Address-and port-dependent | X1′:x1′ = X2′:x2′ iff Y1:y1 = Y2:y2 | Allows packets for X1:x1 from Y1:y1 as long as X1 has previously contacted Y1:y1 |
NAT address pool *¶
A NAT may have several external addresses available to use. The set of addresses is typically called the NAT pool or NAT address pool. Note that NAT address pools are distinct from the DHCP address pools discussed in Chapter 6, although a single device may need to handle both NAT and DHCP address pools.
Address pairing or not? *¶
When a single host behind the NAT opens multiple simultaneous connections, is each assigned the same external IP address (called address pairing) or not?
A NAT’s IP address pooling behavior is said to be arbitrary if there is no restriction on which external address is used for any association. It is said to be paired if it implements address pairing. Pairing is the recommended NAT behavior for all transports. If pairing is not used, the communication peer of an internal host may erroneously conclude that it is communicating with different hosts. For NATs with only a single external address, this is obviously not a problem.
Port overloading *¶
Port overloading is a type of NAT that overloads not only addresses but also ports, where the traffic of multiple internal hosts may be rewritten to the same external IP address and port number. This is a dangerous because if multiple hosts associate with a service on the same external host, it cannot determine the appropriate destination for traffic returning from the external host. For TCP, this is a consequence of all four elements of the connection identifier (source and destination address and port numbers) being identical in the external network among the various connections. Such behavior is now disallowed.
Port parity *¶
Some NATs implement a special feature called port parity. Such NATs attempt to preserve the "parity" (evenness or oddness) of port numbers. Thus, if x1 is even, x1′ is even and vice versa. Although not as strong as port preservation, such behavior is sometimes useful for specific application protocols that use special port numberings (e.g., the Real-Time Protocol, abbreviated RTP, has traditionally used multiple ports, but there are proposed methods for avoiding this issue).
Port parity preservation is a recommended NAT feature but not a requirement. It is also expected to become less important over time as more sophisticated NAT traversal methods become widespread.
Filtering Behavior¶
When a NAT creates a binding for a TCP connection, UDP association, or ICMP traffic, not only does it establish the address and port mappings, but it must also determine its filtering behavior for the returning traffic if it acts as a firewall, which is the common case. The type of filtering a NAT performs, though logically distinct from its address- and port-handling behavior, is often related and the same terminology is used.
A NAT’s filtering behavior is usually related to whether it has established an address mapping. A NAT lacking any form of address mapping is unable to forward any traffic it receives from the outside to the inside because it would not know which internal destination to use. For the most common case of outgoing traffic, when a binding is established, filtering is disabled for relevant return traffic:
- For endpoint-independent filtering behavior, as soon as any mapping is established for an internal host, any incoming traffic is permitted, regardless of source.
- For address-dependent filtering behavior, traffic destined for X1:x1 is permitted from Y1:y1 only if Y1 had been previously contacted by X1:x1.
- For address- and port-dependent filtering behavior, traffic destined for X1:x1 is permitted from Y1:y1 only if Y1:y1 had been previously contacted by X1:x1.
The difference between the last two is that the last form takes the port number y1 into account.
Servers behind NATs¶
A system that wishes to provide a service from behind a NAT is not directly reachable from the outside. In Figure 7-3, if the host with address 10.0.0.3 is to provide a service to the Internet, it cannot be reached without participation from the NAT, for at least two reasons:
- The NAT is acting as the Internet router, so it must agree to forward the incoming traffic destined for 10.0.0.3.
- The IP address 10.0.0.3 is not routable through the Internet and cannot be used to identify the server by hosts in the Internet. Instead, the external address of the NAT must be used to find the server, and the NAT must arrange to properly rewrite and forward the appropriate traffic to the server so that it can operate. This process is most often called port forwarding or port mapping.
Port forwarding *¶
With port forwarding, incoming traffic to a NAT is forwarded to a specific configured destination behind the NAT. This allows servers to provide services to the Internet even though they may be assigned private, nonroutable addresses.
Port forwarding typically requires static configuration of the NAT with the address of the server and the associated port number whose traffic should be forwarded. The port forwarding directive acts like an always-present static NAT mapping. If the server’s IP address is changed, the NAT must be updated with the new addressing information.
Port forwarding also has the limitation that it has only one set of port numbers for each of its (IP address, transport protocol) combinations. Thus, if the NAT has only a single external IP address, it can forward only a single port of the same transport protocol to at most one internal machine (e.g., it could not support two independent Web servers on the inside being remotely accessible using TCP port 80 from the outside).
Hairpinning and NAT Loopback¶
An interesting issue arises when a client wishes to reach a server and both reside on the same, private side of the same NAT. NATs that support this scenario implement so-called hairpinning or NAT loopback.
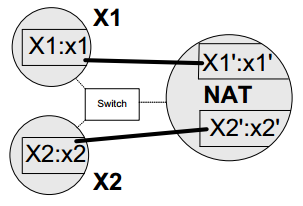
Referring to the figure above, assume that host X1 attempts to establish a connection to host X2. If X1 knows the private addressing information, X2:x2, there is no problem because the connection can be made directly. However, in some cases X1 knows only the public address information, X2′:x2′. In these cases, X1 attempts to contact X2 using the NAT with destination X2′:x2′. The hairpinning process takes place when the NAT notices the existence of the mapping between X2′:x2′ and X2:x2 and forwards the packet to X2:x2 residing on the private side of the NAT. At this point a question arises as to which source address is contained in the packet heading to X2:x2: X1:x1 or X1′:x1′?
If the NAT presents the hairpinned packet to X2 with source addressing information X1′:x1′, the NAT is said to have "external source IP address and port" hairpinning behavior. This behavior is required for TCP NAT [RFC5382]. The justification for requiring this behavior is for applications that identify their peers using globally routable addresses. In our example, X2 may be expecting an incoming connection from X1′ (e.g., because of coordination from a third-party system).
NAT Editors¶
Service Provider NAT (SPNAT) and Service Provider IPv6 Transition¶
NAT Traversal¶
Doubts and Solutions¶
Verbatim¶
p308 on TCP NAT:
One of the tricky problems for a TCP NAT is handling peer-to-peer applications operating on hosts residing on the private sides of multiple NATs [RFC5128]. Some of these applications use a simultaneous open whereby each end of the connection acts as a client and sends SYN packets more or less simultaneously. TCP is able to handle this case by responding with SYN + ACK packets that complete the connection faster than with the three-way handshake, but many existing NATs do not handle it properly. [RFC5382] addresses this by requiring (REQ-2) that a NAT handle all valid TCP packet exchanges, and simultaneous opens in particular. Some peer-to-peer applications (e.g., network games) use this behavior. In addition, [RFC5382] specifies that an inbound SYN for a connection about which the NAT knows nothing should be silently discarded. This can occur when a simultaneous open is attempted but the external host’s SYN arrives at the NAT before the internal host’s SYN. Although this may seem unlikely, it can happen as a result of clock skew, for example. If the incoming external SYN is dropped, the internal SYN has time to establish a NAT mapping for the same connection represented by the external SYN. If no internal SYN is forthcoming in 6s, the NAT may signal an error to the external host.
Some other NAT drawbacks: