Part II-7: TCP/IP Routing Protocols (Gateway Protocols)¶
Routing is not just one of the most important activities at the network layer, but also the function that defines layer 3 of the OSI Reference Model. Routing is what enables small local networks to be linked together to form potentially huge internetworks that can span cities, countries, or even the entire globe. The job of routing is done by special devices called routers, which forward datagrams from network to network, allowing any device to send to any other device, even if the source has no idea where the destination is.
Routers decide how to forward a datagram based on its destination address, which is compared to information the router keeps in special routing tables. These tables contain entries for each of the networks the router knows about, telling the router which adjacent router the datagram should be sent to in order for it to reach its eventual destination.
Routing tables are critically important to the routing process. It is possible for these tables to be manually maintained by network administrators, but this is tedious and time-consuming and doesn’t allow routers to deal with changes or problems in the internetwork. Instead, most modern routers are designed with functionality that lets them share route information with other routers, so they can keep their routing tables up-to-date automatically. This information exchange is accomplished through the use of routing protocols.
The title of this part refers to both routing protocols and gateway protocols. These terms are interchangeable, and the word "gateway" appears in the name of several of the protocols, because historical use of the term "gateway" in early TCP/IP standards to refer to the devices we now call routers. Today, the term "gateway" normally refers not to a router, but to a different type of network interconnection device, so this can be particularly confusing. The term "routing protocol" is now preferred.
Chapter 37. Overview of Key Routing Protocol Concepts¶
This chapter provide an overview of the routing protocol architectures, protocol types, algorithms, and metrics.
Routing Protocol Architectures¶
The word architecture refers to the way that an internetwork is structured. Once you have some networks and routers that you wish to connect together, there are any number of ways that you can do this. The architecture you choose is based on the way that routers are linked, and this has an impact on the way that routing is done and how routing protocols operate.
Core Architecture¶
Early architecture of the Internet consisted of a small number of core routers that contained comprehensive information about the internetwork. When the Internet was very small, adding more routers to this core expanded it. However, each time the core was expanded, the amount of routing information that needed to be maintained grew.
Eventually, the core became too large, so a two-level hierarchy was formed to allow further expansion. Noncore routers were located on the periphery of the core and contained only partial routing information; they relied on the core routers for transmissions that went across the internetwork. There are two special routing protocols:
- The Gateway-to-Gateway Protocol (GGP) was used within the core of the internetwork,
- The Exterior Gateway Protocol (EGP) was used between noncore and core routers.
The noncore routers were sometimes single, stand-alone routers that connected a single network to the core, or they could be sets of routers for an organization.
This architecture served for a while, but it did not scale very well as the Internet grew. The problem was mainly due to the fact that there was only a single level to the architecture:
- Every router in the core had to communicate with every other router.
- Even with peripheral routers being kept outside the core, the amount of traffic in the core kept growing.
Autonomous System (AS) Architecture¶
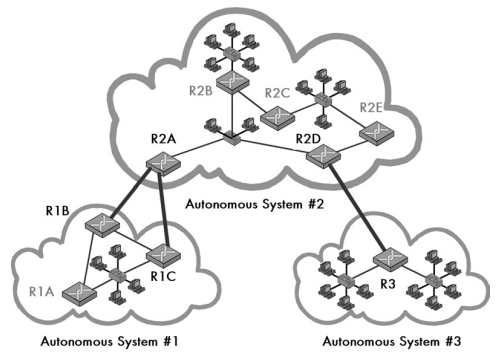
To resolve the scaling problem, a new architecture was created that moved away from the centralized concept of a core toward an architecture that was better suited to a larger and growing internetwork. This decentralized architecture treats the internetwork as a set of independent groups, with each group called an autonomous system (AS). An AS consists of a set of routers and networks controlled by a particular organization or administrative entity, which uses a single consistent policy for internal routing.
The power of this system is that routing on the internetwork as a whole occurs between ASes and not individual routers:
- Information is shared between one and maybe a couple of routers in each AS, not every router in each AS.
- The details of routing within an AS are also hidden from the rest of the internetwork.
This provides both flexibility for each AS to do routing as it sees fit (thus the name autonomous) and efficiency for the overall internetwork. Each AS has its own number, and the numbers are globally managed to make sure that they are unique across an internetwork (such as the Internet).
Large, modern TCP/IP internetworks can contain thousands of routers. To better manage routing in such an environment, routers are grouped into constructs called autonomous systems (ASes), each of which consists of a group of routers managed independently by a particular organization or entity.
Modern Protocol Types: Interior and Exterior Routing Protocols¶
The different nature of routing within an AS and between ASes can be seen in the fact that the following distinct sets of TCP/IP routing protocols are used for each type:
- Interior Routing Protocols. These protocols are used to exchange routing information between routers within an AS. Interior routing protocols are not used between ASes.
- Exterior Routing Protocols. These protocols are used to exchange routing information between ASes. They may in some cases be used between routers within an AS, but they primarily deal with exchanging information between ASes.
Interior routing protocols are used to share routing information within an autonomous system; each AS may use a different interior routing protocol because the system is, as the name says, autonomous. Exterior routing protocols convey routing data between ASes; each AS must use the same exterior protocol to ensure that it can communicate.
Since ASes are just sets of routers, you connect ASes by linking a router in one AS to a router in another AS. Architecturally, an AS consists of a set of routers with two different types of connectivity:
- Internal Routers. Some routers in an AS connect only to other routers in the same AS. These run interior routing protocols.
- Border Routers. Some routers in an AS connect both to routers within the AS and to routers in one or more other ASes. These devices are responsible for passing traffic between the AS and the rest of the internetwork. They run both interior and exterior routing protocols.
Due to its advantages, the AS architecture, an example of which can be seen in the figure below, has become the standard for TCP/IP networks, most notably the Internet. The division of routing protocols into the interior and exterior classifications has thus also become standard, and all modern TCP/IP routing protocols are first subdivided by type in this manner.
Routing Protocol Algorithms and Metrics¶
Another key differentiation of routing protocols is on the basis of the algorithms and metrics they use:
- An algorithm refers to a method that the protocol uses for determining the best route between any pair of networks, and for sharing routing information between routers.
- A metric is a measure of "cost" that is used to assess the efficiency of a particular route.
Since internetworks can be quite complex, the algorithms and metrics of a protocol are very important, and they can be the determining factor in deciding that one protocol is superior to another. There are two routing protocol algorithms that are most commonly encountered: distance vector and link state. There are also protocols that use a combination of these methods or other methods
Distance-Vector (Bellman-Ford) Routing Protocol Algorithm¶
A distance-vector routing algorithm, also called a Bellman-Ford algorithm after two of its inventors, is one where routes are selected based on the distance between networks:
- The distance metric is the number of hops, or routers, between them.
- Routers using this type of protocol maintain information about the distance to all known networks in a table. They regularly send that table to each router they immediately connect with (their neighbors or peers). These routers then update their tables and send those tables to their neighbors. This causes distance information to propagate across the internetwork, so that eventually, each router obtains distance information about all networks on the internetwork.
Distance-vector routing protocols are somewhat limited in their ability to choose the best route. They also are subject to certain problems in their operation that must be worked around through the addition of special heuristics and features. Their chief advantages are simplicity and history (they have been used for a long time).
Link-State (Shortest-Path First) Routing Protocol Algorithm¶
A link-state algorithm selects routes based on a dynamic assessment of the shortest path between any two networks. For that reason, it’s also called a shortest-path first method.
Using this method, each router maintains a map describing the current topology of the internetwork. This map is updated regularly by testing reachability of different parts of the Internet, and by exchanging link-state information with other routers. The determination of the best route (or shortest path) can be made based on a variety of metrics that indicate the true cost of sending a datagram over a particular route.
Link-state algorithms are much more powerful than distance-vector algorithms. They adapt dynamically to changing internetwork conditions, and they also allow routes to be selected based on more realistic metrics of cost than simply the number of hops between networks. However, they are more complicated to set up and use more computer processing resources than distance-vector algorithms, and they aren’t as well established.
Hybrid Routing Protocol Algorithms¶
There are also hybrid protocols that combine features from both types of algorithms (and other protocols that use completely different algorithms). For example, the Border Gateway Protocol (BGP) is a path-vector algorithm, which is somewhat similar to the distance-vector algorithm, but communicates much more detailed route information. It includes some of the attributes of distance-vector and linkstate protocols, but is more than just a combination of the two.
Static and Dynamic Routing Protocols¶
- Static routing simply refers to a situation where the routing tables are manually set up so that they remain static.
- Dynamic routing is the use of routing protocols to dynamically update routing tables.
Thus, all routing protocols are dynamic. There is no such thing as a static routing protocol (unless you consider a network administrator who is editing a routing table a protocol).