Chapter 3. Processes¶
The concept of a process is fundamental to any multiprogramming operating system.
- A process is usually defined as an instance of a program in execution
- For example, if 16 users are running vi at once, there are 16 separate processes (although they can share the same executable code).
- Processes are often called tasks or threads in the Linux source code.
This chapter discusses:
- Static properties of processes
- How process switching is performed by the kernel
- How processes can be created and destroyed
- How Linux supports multithreaded applications. As mentioned in Chapter 1, it relies on so-called lightweight processes (LWP).
Processes, Lightweight Processes, and Threads¶
A process is an instance of a program in execution. You might think of it as the collection of data structures that fully describes how far the execution of the program has progressed.
Processes have a more or less significant life, optionally generate one or more child processes, and eventually die. Each process has just one parent.
From the kernel's point of view, the purpose of a process is to act as an entity to which system resources (CPU time, memory, etc.) are allocated.
Earlier Unix kernels employed a simple model of processes:
- When a process is created, it is almost identical to its parent.
- It receives a (logical) copy of the parent's address space and executes the same code as the parent, beginning at the next instruction following the process creation system call.
- Although the parent and child may share the pages containing the program code (text), they have separate copies of the data (stack and heap), so that changes by the child to a memory location are invisible to the parent (and vice versa).
Multithreaded Applications *¶
Modern Unix systems support multithreaded applications:
- Multithreaded applications are user programs that have many relatively independent execution flows sharing a large portion of the application data structures.
- In such systems, a process is composed of several user threads (or simply threads), each of which represents an execution flow of the process.
- Nowadays, most multithreaded applications are written using standard sets of library functions called pthread (POSIX thread) libraries.
Older versions of the Linux kernel offered no support for multithreaded applications.
From the kernel point of view, a multithreaded application was just a normal process. The multiple execution flows of a multithreaded application were created, handled, and scheduled entirely in User Mode, usually by means of a POSIX-compliant pthread library.
However, such an implementation of multithreaded applications is not very satisfactory. For instance, suppose a chess program uses two threads:
- One of them controls the graphical chessboard, waiting for the moves of the human player and showing the moves of the computer, while the other thread ponders the next move of the game. While the first thread waits for the human move, the second thread should run continuously.
- However, if the chess program is just a single process, the first thread cannot simply issue a blocking system call waiting for a user action; otherwise, the second thread is blocked as well. Instead, the first thread must employ sophisticated nonblocking techniques to ensure that the process remains runnable.
Linux uses lightweight processes to offer better support for multithreaded applications:
- Two lightweight processes may share some resources, like the address space, the open files, etc.
- Whenever one of them modifies a shared resource, the other immediately sees the change.
- The two processes must synchronize themselves when accessing the shared resource.
A straightforward way to implement multithreaded applications is to associate a lightweight process with each thread.
- In this way, the threads can access the same set of application data structures by simply sharing the same memory address space, the same set of open files, etc.
- At the same time, each thread can be scheduled independently by the kernel so that one may sleep while another remains runnable.
Examples of POSIX-compliant pthread libraries that use Linux's lightweight processes are:
- LinuxThreads
- Native POSIX Thread Library (NPTL)
- IBM's Next Generation Posix Threading Package (NGPT)
POSIX-compliant multithreaded applications are best handled by kernels that support "thread groups". In Linux, a thread group is basically a set of lightweight processes that implement a multithreaded application and act as a whole with regards to some system calls such as getpid(), kill(), and _exit().
Process Descriptor¶
To manage processes, the kernel must have a clear picture of what each process is doing, such as:
- The process's priority
- Whether it is running on a CPU or blocked on an event
- What address space has been assigned to it
- Which files it is allowed to address
This is the role of the process descriptor: a task_struct type structure whose fields contain all the information related to a single process. The kernel also defines the task_t data type to be equivalent to struct task_struct.
The process descriptor is rather complex. In addition to a large number of fields containing process attributes, the process descriptor contains several pointers to other data structures that, in turn, contain pointers to other structures. The following figure describes the Linux process descriptor schematically.
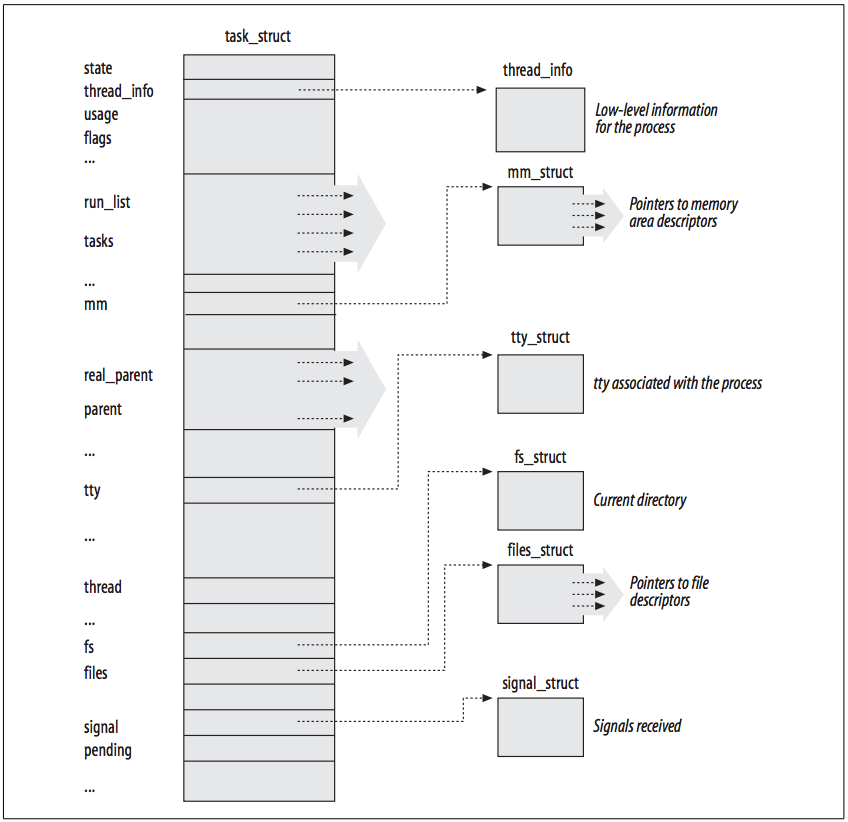
The six data structures on the right side of the figure refer to specific resources owned by the process. Most of these resources will be covered in future chapters. This chapter focuses on two types of fields that refer to the process state and to process parent/child relationships.
Process State¶
The state field of the process descriptor describes what is currently happening to the process. It consists of an array of flags, each of which describes a possible process state. In the current Linux version, these states are mutually exclusive: exactly one flag of state always is set and the remaining flags are cleared.
The following are the possible process states:
TASK_RUNNING. The process is either executing on a CPU or waiting to be executed.TASK_INTERRUPTIBLE. The process is suspended (sleeping) until some condition becomes true. For example, conditions that might wake up the process (put its state back toTASK_RUNNING) can be:- Raising a hardware interrupt
- Releasing a system resource the process is waiting for
- Delivering a signal are examples of conditions that might wake up the process.
TASK_UNINTERRUPTIBLE. LikeTASK_INTERRUPTIBLE, except that delivering a signal to the sleeping process leaves its state unchanged. This process state is seldom used, but is valuable under certain specific conditions in which a process must wait until a given event occurs without being interrupted. For instance, this state may be used when a process opens a device file and the corresponding device driver starts probing for a corresponding hardware device. The device driver must not be interrupted until the probing is complete, or the hardware device could be left in an unpredictable state.TASK_STOPPED. Process execution has been stopped; the process enters this state after receiving aSIGSTOP,SIGTSTP,SIGTTIN, orSIGTTOUsignal.TASK_TRACED. Process execution has been stopped by a debugger. When a process is being monitored by another (such as when a debugger executes aptrace()system call to monitor a test program), each signal may put the process in theTASK_TRACEDstate.
Two additional states of the process can be stored both in the state field and in the exit_state field of the process descriptor; as the field name suggests, a process reaches one of these two states only when its execution is terminated:
EXIT_ZOMBIE. Process execution is terminated, but the parent process has not yet issued await4()orwaitpid()system call to return information about the dead process.* Before thewait()-like call is issued, the kernel cannot discard the data contained in the dead process descriptor because the parent might need it. (See the section Process Removal near the end of this chapter.)EXIT_DEAD. The final state: the process is being removed by the system because the parent process has just issued await4()orwaitpid()system call for it. Changing its state fromEXIT_ZOMBIEtoEXIT_DEADavoids race conditions due to other threads of execution that executewait()-like calls on the same process (see Chapter 5).
Note that there are other wait()-like library functions, such as wait3() and wait(), but in Linux they are implemented by means of the wait4() and waitpid() system calls.
The value of the state field is usually set with a simple assignment. For instance:
p->state = TASK_RUNNING;
The kernel also uses the set_task_state and set_current_state macros: they set the state of a specified process and of the process currently executed, respectively. Moreover, these macros ensure that the assignment operation is not mixed with other instructions by the compiler or the CPU control unit. Mixing the instruction order may sometimes lead to catastrophic results (see Chapter 5).
Identifying a Process¶
Each execution context that can be independently scheduled must have its own process descriptor. Even lightweight processes, which share a large portion of their kernel data structures, have their own task_struct structures.
Process descriptor pointers *¶
The strict one-to-one correspondence between the process and process descriptor makes the 32-bit address of the task_struct structure a useful means for the kernel to identify processes. These addresses are referred to as process descriptor pointers. Most of the references to processes that the kernel makes are through process descriptor pointers.
Process ID *¶
On the other hand, Unix-like operating systems allow users to identify processes by means of a number called the Process ID (or PID), which is stored in the pid field of the process descriptor.
- PIDs are numbered sequentially: the PID of a newly created process is normally the PID of the previously created process increased by one.
- There is an upper limit on the PID values; when the kernel reaches such limit, it must start recycling the lower, unused PIDs.
- By default, the maximum PID number is 32,767 (
PID_MAX_DEFAULT- 1), which equals to 212 × 8 - 1 ; the system administrator may reduce this limit by writing a smaller value into the/proc/sys/kernel/pid_maxfile (/procis the mount point of a special filesystem, see the section Special Filesystems in Chapter 12). - In 64-bit architectures, the system administrator can enlarge the maximum PID number up to 4,194,303.
- By default, the maximum PID number is 32,767 (
When recycling PID numbers, the kernel must manage a pidmap_array bitmap that denotes which are the PIDs currently assigned and which are the free ones. Because a page frame contains 32,768 bits, in 32-bit architectures the pidmap_array bitmap is stored in a single page. In 64-bit architectures, however, additional pages can be added to the bitmap when the kernel assigns a PID number too large for the current bitmap size. These pages are never released.
Thread groups and PID *¶
Linux associates a different PID with each process or lightweight process in the system. There is a tiny exception on multiprocessor systems, which is disussed later this chapter. This approach allows the maximum flexibility, because every execution context in the system can be uniquely identified.
On the other hand, Unix programmers expect threads in the same group to have a common PID. For instance, it should be possible to a send a signal specifying a PID that affects all threads in the group. In fact, the POSIX 1003.1c standard states that all threads of a multithreaded application must have the same PID.
To comply with this standard, Linux makes use of thread groups. The identifier shared by the threads is the PID of the thread group leader:
- The thread group leader is the first lightweight process in the group.
- This identifier is stored in the
tgidfield of the process descriptors.
The getpid() system call returns the value of tgid relative to the current process instead of the value of pid, so all the threads of a multithreaded application share the same identifier.
Most processes belong to a thread group which consists of a single member; as thread group leaders, they have the tgid field equal to the pid field, thus the getpid() system call works as usual for this kind of process.
Later this section shows how it is possible to derive a true process descriptor pointer efficiently from its respective PID. Efficiency is important because many system calls such as kill() use the PID to denote the affected process.
Doubts and Solution¶
Verbatim¶
p83 on process state¶
Moreover, these macros ensure that the assignment operation is not mixed with other instructions by the compiler or the CPU control unit.
Question: What does this mean?