Chatper 2. Data Models and Query Languages¶
Data models are perhaps the most important part of developing software, because they have such a profound effect: not only on how the software is written, but also on how we think about the problem that we are solving.
Most applications are built by layering one data model on top of another. For each layer, the key question is: how is it represented in terms of the next-lower layer? For example:
- As an application developer, you look at the real world and model it in terms of objects or data structures, and APIs that manipulate those data structures. Those structures are often specific to your application.
- When you want to store those data structures, you express them in terms of a general-purpose data model, such as JSON or XML documents, tables in a relational database, or a graph model.
- The engineers who built your database software decided on a way of representing that JSON/XML/relational/graph data in terms of bytes in memory, on disk, or on a network. The representation may allow the data to be queried, searched, manipulated, and processed in various ways.
- On lower levels, hardware engineers have figured out how to represent bytes in terms of electrical currents, pulses of light, magnetic fields, and more.
In a complex application there may be more intermediary levels, such as APIs built upon APIs, but the basic idea is still the same: each layer hides the complexity of the layers below it by providing a clean data model. These abstractions allow different groups (e.g. database engineers and application developers) of people to work together effectively.
There are many different kinds of data models, and every data model embodies assumptions about how it is going to be used. [p28]
It can take a lot of effort to master just one data model. Building software is hard enough, even when working with just one data model and without worrying about its inner workings. But since the data model has such a profound effect on what the software above it can and can't do, it's important to choose one that is appropriate to the application.
This chapter covers a range of general-purpose data models for data storage and querying (point 2 in the preceding list), in particular, comparing the relational model, the document model, and a few graph-based data models. We will also look at various query languages and compare their use cases. In Chapter 3 we will discuss how storage engines work; that is, how these data models are actually implemented (point 3 in the list).
Relational Model Versus Document Model¶
The best-known data model today is probably that of SQL, based on the relational model proposed by Edgar Codd in 1970: data is organized into relations (called tables in SQL), where each relation is an unordered collection of tuples (rows in SQL).
The relational model was a theoretical proposal, and many people at the time doubted whether it could be implemented efficiently. However, by the mid-1980s, relational database management systems (RDBMSes) and SQL had become the tools of choice for most people who needed to store and query data with some kind of regular structure. The dominance of relational databases has lasted around 25‒30 years, an eternity in computing history.
The roots of relational databases lie in business data processing, which was performed on mainframe computers in the 1960s and 1970s. The use cases appear mundane from today's perspective:
- Transaction processing: entering sales or banking transactions, airline reservations, stock-keeping in warehouse.
- Batch processing: customer invoicing, payroll, reporting.
Other databases at that time forced application developers to think a lot about the internal representation of the data in the database. The goal of the relational model was to hide that implementation detail behind a cleaner interface.
Over the years, there have been many competing approaches to data storage and querying:
- The network model and the hierarchical model were the main alternatives in the 1970s and early 1980s, but the relational model came to dominate them.
- Object databases came and went again in the late 1980s and early 1990s.
- XML databases appeared in the early 2000s, but have only seen niche adoption.
Each competitor to the relational model generated a lot of hype in its time, but it never lasted.
As computers became vastly more powerful and networked, they started being used for increasingly diverse purposes. Relational databases turned out to generalize very well, beyond their original scope of business data processing, to a broad variety of use cases. Much of what you see on the web today is still powered by relational databases, be it online publishing, discussion, social networking, ecommerce, games, software-as-a-service productivity applications, etc.
The Birth of NoSQL¶
Now, in the 2010s, NoSQL is the latest attempt to overthrow the relational model's dominance. The name "NoSQL" is unfortunate, since it doesn't actually refer to any particular technology. [p29] A number of interesting database systems are now associated with the NoSQL, and it has been retroactively reinterpreted as Not Only SQL.
There are several driving forces behind the adoption of NoSQL databases:
- A need for greater scalability than relational databases can easily achieve, including very large datasets or very high write throughput
- A widespread preference for free and open source software over commercial database products
- Specialized query operations that are not well supported by the relational model
- Frustration with the restrictiveness of relational schemas, and a desire for a more dynamic and expressive data model
Different applications have different requirements. It therefore seems likely that in the foreseeable future, relational databases will continue to be used alongside a broad variety of nonrelational datastores—an idea that is sometimes called polyglot persistence.
The Object-Relational Mismatch¶
Most application development today is done in object-oriented programming languages, which leads to a common criticism of the SQL data model: if data is stored in relational tables, an awkward translation layer is required between the objects in the application code and the database model of tables, rows, and columns. The disconnect between the models is sometimes called an impedance mismatch.
Object-relational mapping (ORM) frameworks like ActiveRecord and Hibernate reduce the amount of boilerplate code required for this translation layer, but they can't completely hide the differences between the two models.
For example, the following figure illustrates how a LinkedIn profile could be expressed in a relational schema.
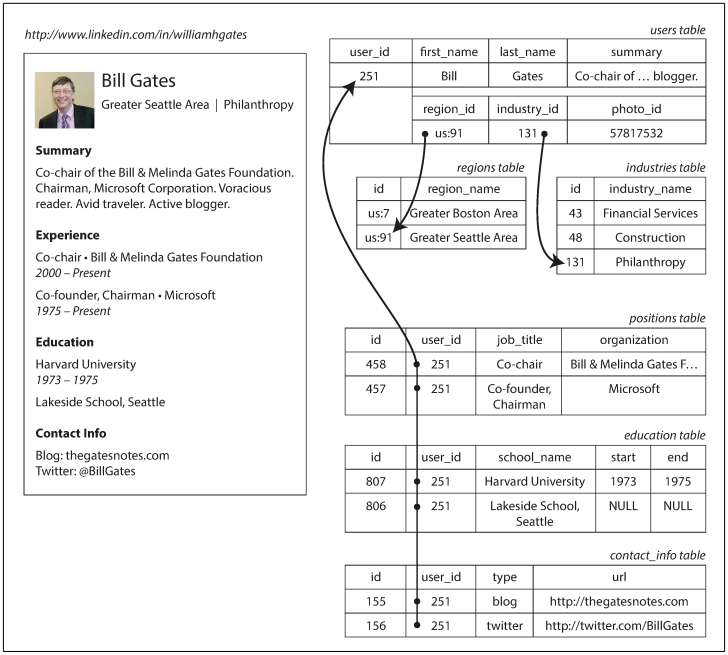
The profile as a whole can be identified by a unique identifier, user_id. Fields like first_name and last_name appear exactly once per user, so they can be modeled as columns on the users table. However, most people have had more than one job in their career (positions), and people may have varying numbers of periods of education and any number of pieces of contact information. There is a one-to-many relationship from the user to these items, which can be represented in various ways:
- In the traditional SQL model (prior to SQL:1999), the most common normalized representation is to put positions, education, and contact information in separate tables, with a foreign key reference to the users table, as in Figure 2-1.
- Later versions of the SQL standard added support for structured datatypes and XML data; this allowed multi-valued data to be stored within a single row, with support for querying and indexing inside those documents. These features are supported to varying degrees by Oracle, IBM DB2, MS SQL Server, and PostgreSQL. A JSON datatype is also supported by several databases, including IBM DB2, MySQL, and PostgreSQL.
- A third option is to encode jobs, education, and contact info as a JSON or XML document, store it on a text column in the database, and let the application interpret its structure and content. In this setup, you typically cannot use the database to query for values inside that encoded column.
For a data structure like a résumé, which is mostly a self-contained document, a JSON representation can be quite appropriate: see the following example 2-1. JSON has the appeal of being much simpler than XML. Document-oriented databases like MongoDB, RethinkDB, CouchDB, and Espresso support this data model.
Example 2-1. Representing a LinkedIn profile as a JSON document
"user_id": 251, "first_name": "Bill", "last_name": "Gates", "summary": "Co-chair of the Bill & Melinda Gates... Active blogger.", "region_id": "us:91", "industry_id": 131, "photo_url": "/p/7/000/253/05b/308dd6e.jpg", "positions": [ { "job_title": "Co-chair", "organization": "Bill & Melinda Gates Foundation" }, { "job_title": "Co-founder, Chairman", "organization": "Microsoft" } ], "education": [ { "school_name": "Harvard University", "start": 1973, "end": 1975 }, { "school_name": "Lakeside School, Seattle", "start": null, "end": null } ], "contact_info": { "blog": "http://thegatesnotes.com", "twitter": "http://twitter.com/BillGates" } }
Some think that the JSON model reduces the impedance mismatch between the application code and the storage layer. However, as we shall see in Chapter 4, there are also problems with JSON as a data encoding format. The lack of a schema is often cited as an advantage, which will be discussed this in Schema flexibility in the document model.
The JSON representation has better locality than the multi-table schema in Figure 2-1. If you want to fetch a profile in the relational example, you need to either perform multiple queries (query each table by user_id) or perform a messy multi-way join between the users table and its subordinate tables. In the JSON representation, all the relevant information is in one place, and one query is sufficient.
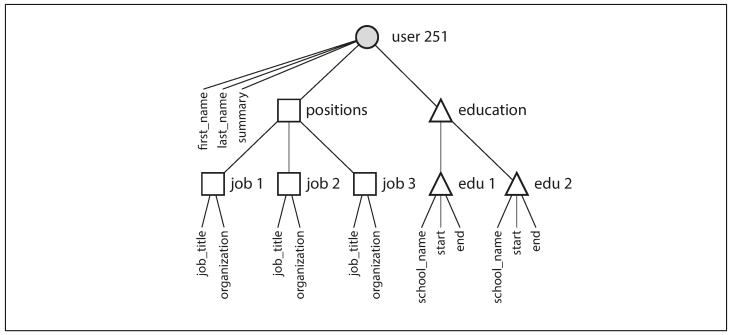
The one-to-many relationships from the user profile to the user's positions, educational history, and contact information imply a tree structure in the data, and the JSON representation makes this tree structure explicit (see Figure 2-2 below).
Many-to-One and Many-to-Many Relationships¶
In the previous example, region_id and industry_id are given as IDs, not as plain-text strings "Greater Seattle Area" and "Philanthropy". Why?
If the user interface has free-text fields for entering the region and the industry, it makes sense to store them as plain-text strings. But there are advantages to having standardized lists of geographic regions and industries, and letting users choose from a drop-down list or autocompleter:
- Consistent style and spelling across profiles
- Avoiding ambiguity (e.g., if there are several cities with the same name)
- Ease of updating. The name is stored in only one place, so it is easy to update across the board if it ever needs to be changed (e.g., change of a city name due to political events)
- Localization support. When the site is translated into other languages, the stand‐ ardized lists can be localized, so the region and industry can be displayed in the viewer's language
- Better search. For example, a search for philanthropists in the state of Washington can match this profile, because the list of regions can encode the fact that Seattle is in Washington (which is not apparent from the string "
Greater Seattle Area")
Whether you store an ID or a text string is a question of duplication:
- When you use an ID, the information that is meaningful to humans (such as the word Philanthropy) is stored in only one place, and everything that refers to it uses an ID (which only has meaning within the database).
- When you store the text directly, you are duplicating the human-meaningful information in every record that uses it.
The advantage of using an ID is that because it has no meaning to humans, it never needs to change: the ID can remain the same, even if the information it identifies changes. Anything that is meaningful to humans may need to change sometime in the future. If that information is duplicated, all the redundant copies need to be updated. That incurs write overheads, and risks inconsistencies (where some copies of the information are updated but others aren't). Removing such duplication is the key idea behind normalization in databases.
Unfortunately, normalizing this data requires many-to-one relationships (e.g. many people live in one particular region, many people work in one particular industry), which don't fit nicely into the document model.
- In relational databases, it's normal to refer to rows in other tables by ID, because joins are easy.
- In document databases, joins are not needed for one-to-many tree structures, and support for joins is often weak.
If the database itself does not support joins, you have to emulate a join in application code by making multiple queries to the database. In the example, the lists of regions and industries are probably small and slow-changing enough that the application can simply keep them in memory. But nevertheless, the work of making the join is shifted from the database to the application code.
Even if the initial version of an application fits well in a join-free document model, data has a tendency of becoming more interconnected as features are added to applications. For example, consider some changes we could make to the résumé example:
- Organizations and schools as entities. In the previous description,
organizationandschool_nameare just strings. Perhaps they should be references to entities instead? Then:- Each organization, school, or university could have its own web page (with logo, news feed, etc.)
- Each résumé could link to the organizations and schools that it mentions, and include their logos and other information.
- Recommendations. For instance, you want to add a new feature: one user can write a recommendation for another user. The recommendation is shown on the résumé of the user who was recommended, together with the name and photo of the user making the recom‐ mendation. If the recommender updates their photo, any recommendations they have written need to reflect the new photo. Therefore, the recommendation should have a reference to the author's profile.
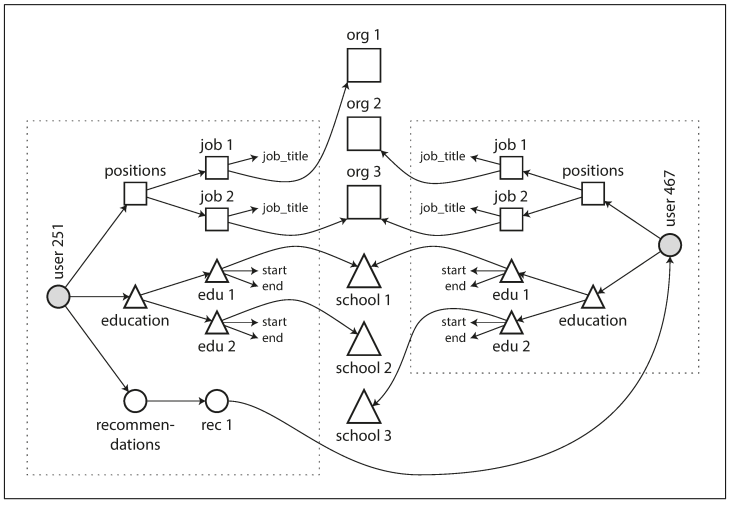
Figure 2-4 below illustrates how these new features require many-to-many relationships. The data within each dotted rectangle can be grouped into one document, but the references to organizations, schools, and other users need to be represented as references, and require joins when queried.
Are Document Databases Repeating History?¶
While many-to-many relationships and joins are routinely used in relational databases, document databases and NoSQL reopened the debate on how best to represent such relationships in a database. This debate is much older than NoSQL; in fact, it goes back to the very earliest computerized database systems.
The most popular database for business data processing in the 1970s was IBM's Information Management System (IMS), originally developed for stock-keeping in the Apollo space program and first commercially released in 1968. It is still in use and maintained today, running on OS/390 on IBM mainframes.
The design of IMS used a fairly simple data model called the hierarchical model, which has some remarkable similarities to the JSON model used by document databases. It represented all data as a tree of records nested within records, much like the JSON structure of Figure 2-2.
Like document databases, IMS worked well for one-to-many relationships, but it made many-to-many relationships difficult, and it didn't support joins. Developers had to decide whether to duplicate (denormalize) data or to manually resolve references from one record to another. These problems of the 1960s and 1970s were very much like the problems that developers are running into with document databases today.
Various solutions were proposed to solve the limitations of the hierarchical model. The two most prominent were:
- Relational model (which became SQL, and took over the world)
- Network model (which initially had a large following but eventually faded into obscurity).
The "great debate" between these two camps lasted for much of the 1970s.
The network model¶
The network model was standardized by a committee called the Conference on Data Systems Languages (CODASYL) and implemented by several different database vendors; it is also known as the CODASYL model.
The CODASYL model was a generalization of the hierarchical model. In the tree structure of the hierarchical model, every record has exactly one parent; in the network model, a record could have multiple parents. For example, there could be one record for the "Greater Seattle Area" region, and every user who lived in that region could be linked to it. This allowed many-to-one and many-to-many relationships to be modeled.
The links between records in the network model were not foreign keys, but more like pointers in a programming language (while still being stored on disk). The only way of accessing a record was to follow a path from a root record along these chains of links. This was called an access path.
In the simplest case, an access path could be like the traversal of a linked list: start at the head of the list, and look at one record at a time until you find the one you want. But in a world of many-to-many relationships, several different paths can lead to the same record, and a programmer working with the network model had to keep track of these different access paths in their head.
A query in CODASYL was performed by moving a cursor through the database by iterating over lists of records and following access paths. If a record had multiple parents (i.e., multiple incoming pointers from other records), the application code had to keep track of all the various relationships. Even CODASYL committee members admitted that this was like navigating around an n-dimensional data space.
Although manual access path selection was able to make the most efficient use of the very limited hardware capabilities in the 1970s (such as tape drives, whose seeks are extremely slow), the problem was that they made the code for querying and updating the database complicated and inflexible. With both the hierarchical and the network model, if you didn't have a path to the data you wanted, you were in a difficult situation. You could change the access paths, but then you had to go through a lot of handwritten database query code and rewrite it to handle the new access paths. It was difficult to make changes to an application's data model.
The relational model¶
By contrast, the relational model laid out all the data in the open: a relation (table) is simply a collection of tuples (rows):
- There are no labyrinthine nested structures, no complicated access paths to follow if you want to look at the data.
- You can read any or all of the rows in a table, selecting those that match an arbitrary condition.
- You can read a particular row by designating some columns as a key and matching on those.
- You can insert a new row into any table without worrying about foreign key relationships to and from other tables. (Foreign key constraints allow you to restrict modifications, but such constraints are not required by the relational model. Even with constraints, joins on foreign keys are performed at query time, whereas in CODASYL, the join was effectively done at insert time.)
In a relational database, the query optimizer automatically decides which parts of the query to execute in which order, and which indexes to use. Those choices are effectively the "access path", but the big difference is that they are made automatically by the query optimizer, not by the application developer, so we rarely need to think about them.
If you want to query your data in new ways, you can just declare a new index, and queries will automatically use whichever indexes are most appropriate. You don't need to change your queries to take advantage of a new index. (See also Query Languages for Data) The relational model thus made it much easier to add new features to applications.
Query optimizers for relational databases are complicated beasts, and they have consumed many years of research and development effort. But a key insight of the relational model was this: you only need to build a query optimizer once, and then all applications that use the database can benefit from it. If you don't have a query optimizer, it's easier to handcode the access paths for a particular query than to write a general-purpose optimize, but the general-purpose solution wins in the long run.
Comparison to document databases¶
Document databases reverted back to the hierarchical model in one aspect: storing nested records (one-to-many relationships, like positions, education, and contact_info in Figure 2-1) within their parent record rather than in a separate table.
However, when it comes to representing many-to-one and many-to-many relationships, relational and document databases are not fundamentally different: in both cases, the related item is referenced by a unique identifier, which is called a foreign key in the relational model and a document reference in the document model. That identifier is resolved at read time by using a join or follow-up queries. To date, document databases have not followed the path of CODASYL.
Relational Versus Document Databases Today¶
There are many differences to consider when comparing relational databases to document databases, including:
This chapter concentrates only on the differences in the data model.
The main arguments in favor of the document data model are:
- Schema flexibility
- Better performance due to locality
- For some applications it is closer to the data structures used by the application
The relational model counters by providing better support for joins, and many-to-one and many-to-many relationships.
Which data model leads to simpler application code?¶
If the data in your application has a document-like structure (i.e., a tree of one-to-many relationships, where typically the entire tree is loaded at once), then it's probably a good idea to use a document model. The relational technique of shredding (splitting a document-like structure into multiple tables, like positions, education, and contact_info in Figure 2-1) can lead to cumbersome schemas and unnecessarily complicated application code.
The document model has limitations: for example, you cannot refer directly to a nested item within a document, but instead you need to say something like "the second item in the list of positions for user 251" (much like an access path in the hierarchical model). However, as long as documents are not too deeply nested, that is not usually a problem.
The poor support for joins in document databases may or may not be a problem, depending on the application. For example, many-to-many relationships may never be needed in an analytics application that uses a document database to record which events occurred at which time.
However, if your application does use many-to-many relationships, the document model becomes less appealing:
- It's possible to reduce the need for joins by denormalizing, but then the application code needs to do additional work to keep the denormalized data consistent.
- Joins can be emulated in application code by making multiple requests to the database, but that also moves complexity into the application and is usually slower than a join performed by specialized code inside the database.
In such cases, using a document model can lead to significantly more complex application code and worse performance.
In general, which data model leads to simpler application code depends on the kinds of relationships that exist between data items. For highly interconnected data, the document model is awkward, the relational model is acceptable, and graph models (see Graph-Like Data Models) are the most natural.
Schema flexibility in the document model¶
Most document databases, and the JSON support in relational databases, do not enforce any schema on the data in documents. XML support in relational databases usually comes with optional schema validation. No schema means that arbitrary keys and values can be added to a document, and when reading, clients have no guarantees as to what fields the documents may contain.
Document databases are sometimes called schemaless, but that's misleading, as the code that reads the data usually assumes some kind of structure, i.e., there is an implicit schema, but it is not enforced by the database; a more accurate term is schema-on-read.
- schema-on-read: the structure of the data is implicit, and only interpreted when the data is read.
- schema-on-write: the traditional approach of relational where the schema is explicit and the database ensures all written data conforms to it.
Schema-on-read is similar to dynamic (runtime) type checking in programming languages, whereas schema-on-write is similar to static (compile-time) type checking. Just as the advocates of static and dynamic type checking have big debates about their relative merits, enforcement of schemas in database is a contentious topic, and in general there's no right or wrong answer.
The difference between the two approaches is particularly noticeable when an application wants to change the format of its data. For example, say you are currently storing each user's full name in one field, and you instead want to store the first name and last name separately. In a document database, you would just start writing new documents with the new fields and have code in the application that handles the case when old documents are read. For example:
if (user && user.name && !user.first_name) {
// Documents written before Dec 8, 2013 don't have first_name
user.first_name = user.name.split(" ")[0];
}
On the other hand, in a "statically typed" database schema, you would typically perform a migration along the lines of:
ALTER TABLE users ADD COLUMN first_name text; UPDATE users SET first_name = split_part(name, ' ', 1); -- PostgreSQL UPDATE users SET first_name = substring_index(name, ' ', 1); -- MySQL
Schema changes have a bad reputation of being slow and requiring downtime. This reputation is not entirely deserved: most relational database systems execute the ALTER TABLE statement in a few milliseconds. MySQL is a notable exception: it copies the entire table on ALTER TABLE, which can mean minutes or even hours of downtime when altering a large table, although various tools exist to work around this limitation (e.g. pt-online-schema-change, lhm and gh-ost).
Running the UPDATE statement on a large table is likely to be slow on any database, since every row needs to be rewritten. If that is not acceptable, the application can leave first_name set to its default of NULL and fill it in at read time, like it would with a document database.
The schema-on-read approach is advantageous if the items in the collection don't all have the same structure for some reason (i.e., the data is heterogeneous). For example:
- There are many different types of objects, and it is not practical to put each type of object in its own table.
- The structure of the data is determined by external systems over which you have no control and which may change at any time.
In situations like these, a schema may hurt more than it helps, and schemaless documents can be a much more natural data model. But in cases where all records are expected to have the same structure, schemas are a useful mechanism for documenting and enforcing that structure. Schemas and schema evolution are discussed in more detail in Chapter 4.
Data locality for queries¶
A document is usually stored as a single continuous string, encoded as JSON, XML, or a binary variant thereof (such as MongoDB's BSON). If your application often needs to access the entire document (for example, to render it on a web page), there is a performance advantage to this storage locality. If data is split across multiple tables, like in Figure 2-1, multiple index lookups are required to retrieve it all, which may require more disk seeks and take more time.
The locality advantage only applies if you need large parts of the document at the same time. The database typically needs to load the entire document, even if you access only a small portion of it, which can be wasteful on large documents. On updates to a document, the entire document usually needs to be rewritten; only modifications that don't change the encoded size of a document can easily be performed in place. For these reasons, it is generally recommended that you keep documents fairly small and avoid writes that increase the size of a document. These performance limitations significantly reduce the set of situations in which document databases are useful.
It's worth pointing out that the idea of grouping related data together for locality is not limited to the document model. For example:
- Google's Spanner database offers the same locality properties in a relational data model, by allowing the schema to declare that a table's rows should be interleaved (nested) within a parent table.
- Oracle allows the same, using a feature called multi-table index cluster tables.
- The column-family concept in the Bigtable data model (used in Cassandra and HBase) has a similar purpose of managing locality.
See more about locality in Chapter 3.
Convergence of document and relational databases¶
Most relational database systems (other than MySQL) have supported XML since the mid-2000s. This includes functions to make local modifications to XML documents and the ability to index and query inside XML documents, which allows applications to use data models very similar to what they would do when using a document database.
The follow databases also have a similar level of support for JSON documents:
- PostgreSQL since version 9.3
- MySQL since version 5.7
- IBM DB2 since version 10.5
Given the popularity of JSON for web APIs, it is likely that other relational databases will follow in their footsteps and add JSON support.
On the document database side, RethinkDB supports relational-like joins in its query language, and some MongoDB drivers automatically resolve database references (effectively performing a client-side join, although this is likely to be slower than a join performed in the database since it requires additional network round-trips and is less optimized).
It seems that relational and document databases are becoming more similar over time, and that is a good thing: the data models complement each other. If a database is able to handle document-like data and also perform relational queries on it, applications can use the combination of features that best fits their needs.
A hybrid of the relational and document models is a good route for databases to take in the future.